| Home | Up | Questions? |
Weighted Fair Queuing is a scheduling policy that attempts to share service among a set of queues. Service is shared, not equally, but in proportion to the weights associated with each queue.
For example, we might have 3 queues, weighted 60, 30, and 10. That is the first queue should get 60% of the service, the second 30%, and the last only 10% of the service.
In general, we are given a set of n queues; 1 <= n an integer. Associated with each queue, i, is a goal weight,
0 < gi.If G is the sum of all weights, then weighted fair queueing should give queue i a share of service equal to
0 < gi/G <= 1
The conceptual definition of Weighted Fair Queuing is that at any given time when we need to select the next item to service, we generate a random number and use it to select from the queues according to the probability given by gi/G. While this is correct conceptually, there is the possibility that either due to the specific random sequence generated, or due to non-randomness in a pseudo-randomly generated sequence, the actual service provided to a queue may vary (possibly substantially) from its weight.
A deterministic method of picking which queue to service should avoid random variance in servicing; the next queue to be serviced will be determined strictly by the weights, without random variation.
To compute the correct next queue to be serviced, it will be necessary to remember how much service each queue has already had. For each queue i, we keep a history, hi of the number of times that queue i has been serviced. In the limit, we would want the ratios of histories for two queues, i and j, to approach the ratios of their goal weights,
gi/gj = hi/hjor if we define H to be the sum over all the hi, then we want
gi/G = hi/H
For the short term, since the histories are integer values, it is not possible to make this true, due to digitization effects. For example, if we have only two queues which each have the same weight, then we would expect each queue to be served equally. So for 14 queue services, we would expect each to be served 7 times. For the 15th queue service, however, we then must service one queue, or the other, resulting in histories of 7 and 8; the ratios are not the same. While this is necessary for the 15th queue service, we would expect a deterministic weighted fair schedule then service the other queue next, giving histories of 8 and 8, and restoring the correct ratio of service.
For deterministic weighted fair queues, we service queue i if i is the "furthest" behind -- the furthest from having the correct ratio. We pick queue i with the largest,
gi/G - hi/HThe first operand is the desired ratio of service; the second operand is the ratio of service that queue i has received. The difference is a measure of how far off we are from the goal. If we are servicing more than our goal, the second operand will be greater than the goal, and this quantity will be negative. So the queue with the largest (positive) difference is the queue that is furthest behind. Servicing this queue will move us back towards the ratios that we want.
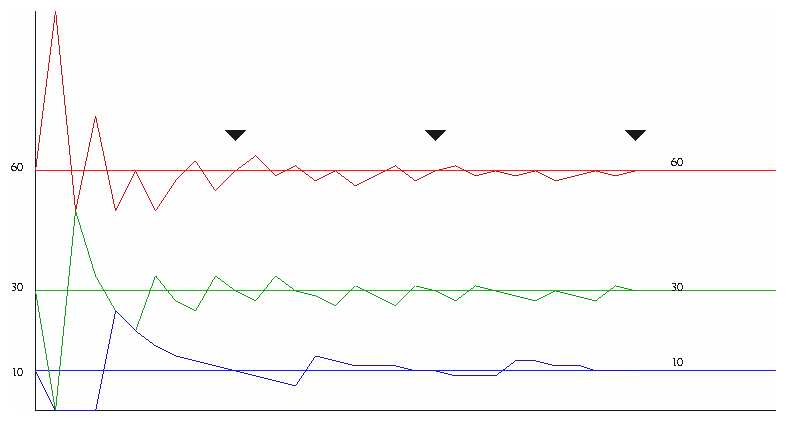
Notice that the amount of history that we keep affects the overall computation of how close we are to meeting our goals. In Figure 1, for example, we plot the desired goals of 60/30/10 and the actual percentage of total service applied to each queue. The actual percentages vary widely for the first few services, but tend towards the desired goals fairly quickly.
Figure 1. Desired and Actual percentage service for Weighted Fair Queuing.
Notice also the 3 locations (marked by the triangles) where we hit the desired goals for all queues. The service order is identical for each of the 3 periods defined by these points, so, in some sense, each of these 3 periods is identical. Yet the percentage of total service continues to approach the desired goal ratios as service continues.
Notice that for two queues, i and j, if
gi/G - hi/H >= gj/G - hj/Hthen, since G and H are both non-negative,
(gi*H - hi*G)/(G*H) >= (gj*H - hj*G)/(G*H)and thus,
(gi*H - hi*G) >= (gj*H - hj*G)Thus we can avoid dividing in our computations. This also avoids the start-up problem when H is zero, or the need for floating point numbers. We select queue i which has maximal
di = (gi*H - hi*G)If we have two (or more queues) with the same values, we would pick the queue i with the largest goal, gi. This works to minimize the total variance on the next iteration since if gi > gj, then
(gi*(H+1) - (hi+1)*G) > (gj*(H+1) - (hj+1)*G)
(gi*H+gi - hi*G - G) > (gj*H+gj - hj*G - G)
(gi*H - hi*G) + (gi - G) > (gj*H - hj*G) + (gj - G)
For coding, we define arrays g[n] and h[n], and sums G and H. Selecting the next queue is a search over all queues, looking for the maximum value of
di = g[i]*H-h[i]*G;In the best case, all differences will be zero; otherwise at least one difference will be positive.
Two problems remain:
There are some natural places where the hi can be set to zero:
We should be able to show that if all queues stay non-empty, then (gi*H - hi*G) will be zero for all i when H is a multiple of G/gcd, where gcd is the greatest common denominator of the gi for all i. That is, since we are fairly and deterministicly servicing the queues, then when it is possible for the number of services to be evenly divided among the queues in the goal ratios, then we will have done that and the differences from the goal ratios will all be zero.
In the example of weights of 60,30,10; we will have all zero differences at least after 10 services (the sum of 60 + 30 + 10 divided by 10, the greatest common divisor of the three).
Another approach is to notice that while H and hi grow without bounds, and hence the terms (gi*H) and (hi*G) grow without bounds, the difference, di = gi*H - hi*G, is bounded.
If we were to store di for each queue, we would need to be able to update it. We can define di as a function of time t, t = 0, 1, ... as:
di(t) = (gi*H(t) - hi(t)*G)where,
As the system progresses thru time, we have at time t+1,
di(t+1) = (gi*H(t+1) - hi(t+1)*G)If we define the selection function s(i,t) to be 1 if queue i is selected for service at time t, and zero otherwise, then
and
hi(t+1) = hi(t) + s(i,t)
H(t+1) = H(t) +1So,
di(t+1) = (gi*H(t+1) - hi(t+1)*G) di(t+1) = (gi*(H(t)+1) - (hi(t)+s(i,t))*G) di(t+1) = (gi*H(t) - hi(t)*G) + gi - s(i,t))*G di(t+1) = di(t) + gi - s(i,t))*G
This allows us to easily compute di(t) and to keep it updated over time with one addition for most queues, and one addition and one subtraction for the selected queue. In addition, these differences are bounded over time. Figure 2 shows the plot of di(t) versus time t for the 60/30/10 example.
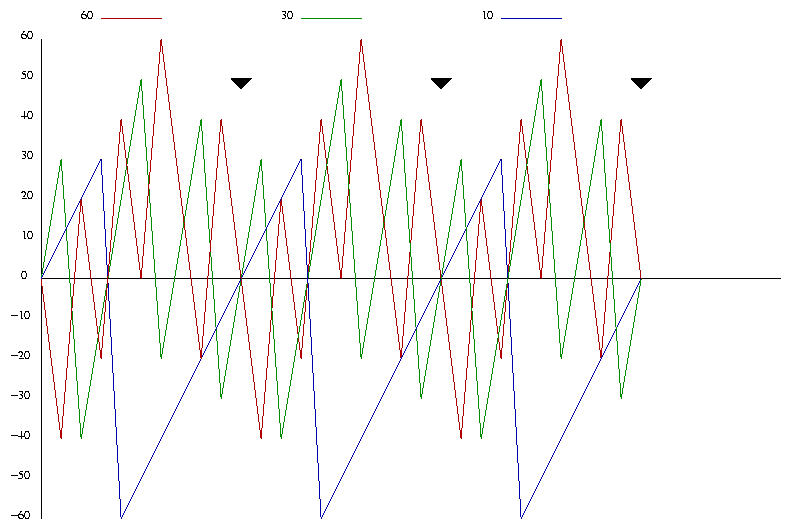
Figure 2. Difference functions versus time for 60/30/10 example.
From Figure 2, particularly for the blue line (queue with 10% of service), we see that the value for each queue increases at a fixed rate (lower rate for lower service level), until it becomes the largest value. At that point, the queue is serviced, and drops. After dropping, it begins to climb again until it is largest. The more service, the faster the climb (climbs at a rate gi) and the lower the drop (drops at a rate gi - G).
The difference value can be thought of as an indication of whether the queue has gotten too much service (negative), too little service (positive), or exactly the right amount of service (zero). The magnitude of the value is an indication of how far from desired the queue is.
This treatment is similar to the Bresenham Line-Drawing Algorithm.
When a queue becomes empty, the remaining queues may get significantly more service. Consider the 60/30/10 example for different subsets of empty queues:
| 60 | .60 | - | .85 | .66 | 1.00 | - | - |
| 30 | .30 | .75 | - | .33 | - | 1.00 | - |
| 10 | .10 | .25 | .14 | - | - | - | 1.00 |
So, if we have 3 non-empty queues, and then the first becomes empty, the proportion of the queue allocated to the second queue jumps from 30 percent to 75 percent. If the first queue becomes non-empty again, the second queue drops back from 75 percent to 30 percent.
Note that if we have been servicing a set of non-empty queues, and one of them becomes empty, the subsequence of history for the remaining non-empty queues is close to the desired goal weights for these non-empty queues (after adjusting G to be the sum of the non-empty queues). That is, in the 60/30/10 history sequence:
1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0 1 0 0 1 0 0 1 0 2 0In this sequence, we have 84 services for queue 0, 42 for queue 1, and 14 for queue 2; a ratio of 6/3/1.
If we look only at the subsequence consisting of the 30/10 part (queues 1 and 2), we have:
1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2 1 1 1 2which is a subsequence of 42 for queue 1, and 14 for queue 2; a ratio of 3/1.
So, if we continue with the given difference values, we should continue serving at the desired goal ratios, if we adjust G to be the sum of the non-empty queues at all times, and do not service (or compute difference values) for empty queues.
The difference values effectively encode for each queue whether or not it has received enough or too much service. Continuing to use these values as the basis for the continuing stream of computed difference values allows the limited amount of important past history to be reflected in how queues are scheduled, while maintaining the weighted fair queueing and boundedness of the values.
A queue could go empty at any time. If we look at the patterns of difference values, while they are bounded, the values which result from an empty queue may not be the same as those which would have resulted from never having had the empty queue at all.
For example, in the 60/30/10 example, the possible values of di are:
Queue 0 (60) Queue 1 (30) Queue 2 (10) -20 -10 30 -20 40 -20 -40 30 10 0 0 0 0 50 -50 20 -40 20 20 10 -30 40 -30 -10 40 20 -60 60 -20 -40
If we consider only the subset of this set when Queue 0 becomes empty -- which to say when Queue 0 has just been serviced, we have:
Queue 0 (60) Queue 1 (30) Queue 2 (10) following sequence of 1 and 2 0 50 -50 1 1 1 2 -20 40 -20 1 1 2 1 20 10 -30 1 1 2 1 -40 30 10 1 2 1 1 0 0 0 1 2 1 1 -20 -10 30 2 1 1 1
But if we look at the set of difference values that can be generated by just two queues, 30 and 10, starting from zero, we find:
Queue 1 (30) Queue 2 (10) following sequence 20 -20 1 1 1 2 10 -10 1 1 2 1 0 0 1 2 1 1 -10 10 2 1 1 1
So the sequences of values that would result from starting from a 60/30/10 queue set and then having the first queue go empty would be significantly different from the sequences of values that would result from a "normal" 30/10 queue set.
We can define how a 60/30/10 state when 60 goes empty should map to a 30/10 state by looking at the order in which the two non-empty queues are serviced. That is, if the difference values are (-20, 40, -20) and queue 0 goes empty, then we would want to map to a new state of (*, 10, -10), so that the two remaining queues would continue to be serviced in the same order.
This suggests that we have the following mapping, where G changes from 100 to 40
| queue 0 (60) | queue 1 (30) | queue 2 (10) | following sequence | new queue 1 (30) | new queue2 (10) |
| 0 | 50 | -50 | 1 1 1 2 | 20 | -20 |
| -20 | 40 | -20 | 1 1 2 1 | 10 | -10 |
| 20 | 10 | -30 | 1 1 2 1 | 10 | -10 |
| -40 | 30 | 10 | 1 2 1 1 | 0 | 0 |
| 0 | 0 | 0 | 1 2 1 1 | 0 | 0 |
| -20 | -10 | 30 | 2 1 1 1 | -10 | 10 |
From this we can compute the changes that are necessary to define the new difference values. These values appear to have certain regularities, but do not appear to be easily predicted or computed. If we think about what we are doing, we are mapping from an n-dimensional space to a (n-1)-dimensional space where only a subset of the integer valued points of the space are valid.
The points of each n-dimensional space start at the origin (all values zero) and define a path, eventually returning to the origin. This suggests that we maintain our current definition of the system (same number of queues and values), simply skipping any empty queues which are selected for servicing until we cycle back to the origin. When we return to the origin, we can then adjust the structure of the system (the value of n and the value of G), and continue from that point.
This approach means that we will always be on one of the well-defined subsets of valid points and we will maintain the weighted fair queuing ratios. As long as the length of the cycle is short, we should not need to skip very many empty queues.
Going the other way, when an empty queue becomes non-empty poses more of a problem for this approach. Just as we cannot simply use the existing difference values when a queue becomes empty, so we cannot when a queue becomes non-empty. Rather we have to adjust the difference values when we add a queue, unless all difference values are zero.
Another view of this work is that weighted fair queueing, as long as the queues are non-empty, is always going to be a cycle. The length of the cycle is at most G. (If all weights are reduced by the greatest common denominator of the weights, then the length is G.)
If the cycle is precomputed, then scheduling is just stepping around the cycle, servicing queues as we go. The problem then becomes how to define the cycle. One approach is to run the algorithm given above (with difference values) from a state of zero for all difference values, until we get back to this same zero state again.
Trey Jones suggests the following example:
Applying our algorithm, we generate a cycle of:
Queue Goal A 16 B 1 C 1 D 1 E 1
It is argued that a better cycle is:A B A A A C A A A D A A A E A A A A A A
which has the advantage of a more constant level of service for queue A; the level of service for B, C, D, and E does not change.A B A A A A C A A A A D A A A A E A A A
An alternative algorithm for producing the algorithm is to first construct sequences of each queue, repeated as many times as the weight for that queue. Then sequences are merged together (interleaved), until only one sequence is left. The algorithm must define the order in which sequences are merged.
For example, an algorithm, based on Huffman coding, is defined by picking the two shortest sequences and merging them. Thus, a weighting of 17,13,10,10,5,3 would produce the following sequences of merges:
| Operation | Resulting sequences |
| Start | 17,13,10,10,5,3 |
| Merge 5,3 | 17,13,10,10,8 |
| Merge 10,8 | 17,13,10,18 |
| Merge 13,10 | 17,23,18 |
| Merge 18,17 | 35,23 |
| Merge 35,23 | 58 |
James Peterson
February, 2001
From Trey Jones:
So, I have a suggestion for dealing with the queues that I think avoids the whole empty-queue, queue-becoming-non-empty problem. The important assumptions follow: --Arbitrary granularity of queues is not allowed (e.g., there will be no 60.0001/30.0000002/9.9998998 division of queues). --Frequency of queue weighting updates is "reasonable", i.e., on a human time-scale, and not some crazy adaptive thing that gets changed every time 10 packets go by. --In the case of sometimes-empty queues, providing the right ratio of *opportunities to process the queue* is sufficient, and we don't need to worry about the actual number of times the queue was processed. The short version is this: maintain a circular linked list (conceptually--in reality an array would be nice) that has a deterministic order for servicing the queues. In the A:60/B:30/C:10 situation, you'd have the following array: A B A B A A C A B A. You don't have to worry about what constitutes "recent" history, the queue-becoming-non-empty problem, or changes in weights causing a sudden skew in favor of or against particular queues. If arbitrary granularity of queues is allowed, then this obviously won't work. Is it reasonable to assume percent or per-mille level of granularity? I think a 1000-element array (using no more than 1K of memory) would be acceptable. Here's an algorithm I came up with to create the array. It isn't particularly efficient, but it is straightforward. If it takes three seconds to run (which would be pretty slow, I think) and gets run once a day, it shouldn't matter. It can also be run by the interface that assigns the queue weights, and then the final array is all that needs to be shipped out to the BSW. Start with the relative weights, then divide by the largest common factor so that the elements are relatively prime. This may actually be the hardest part.. but we only need to factor one number--the smallest weight--so maybe it isn't too bad. If we allow per-mille weights, then we wouldn't have to factor a number larget than 1000 (actually 500, since you'd need two queues or you wouldn't care), and you only need to try prime factors up to sqrt(500)=22.3... , so 2,3,5,7,11,13,17,19, and 23 just to be safe.. okay, that's not bad. An example: A 60 B 30 C 10 --> A 6 B 3 C 1 Populate a linked list with the number of elements of the most weighted queue: A A A A A A length:6 Recursively combine the next n most weighted queues to create a new list with a length up to but not exceeding the current length: B B C B length: 4 (details hidden for now) Fold the shorter list into the longer one. Our folding constant, f, is (longlength/shortlength): f = 6/4 = 1.5 Insert elements of the shorter list into the appropriate positions of the longer list that correspond to multiples of f: 1f = 1.5 = between 1 and 2 2f = 3 = before 3 (so things don't pile up at the end, and so rounding errors don't matter) 3f = 4.5 = between 4 and 5 4f = 6 = before 6 This is particularly easy with a linked list, since you can keep count of the number of elements you've seen of the longer list while inserting elements of the shorter list. Result: A B A B A A C A B A Another example: A 5 B 4 C 4 D 4 E 3 F 2 G 1 Initital list A A A A A length:5 Now make a new list up to length 5, which would be just: B B B B length:4 Fold with f = 5/4 = 1.25: A B A B A B A B A length:9 Now make up a new list, up to length 9. From C 4 and D 4: C C C C length:4 fold in D D D D with f = 1: D C D C D C D C length:8 fold into A B ..., with f = 9/8: A D B C A D B C A D B C A D B C A length:17 now make a new list, up to length 17. From E 3, F 2, G 1: E E E length:3 F F length:2 G length:1, fold with f = 2/1: F G F length:3, fold with f = 3/3: F E G E F E length:6, fold with f = 17/6 = 2.833 A D F B C A E D B C G A D B E C A D F B C E A length:23 You get nice results with a bunch of similarly weighted queues, or a bimodal distribution of weights. For a distribution with one very heavy outlier: A 20 B 1 C 1 D 1 A A A A A A D A A A A A A A C A A A A A A B A In a situation like this last one, if it were frequent, we could compress the list in the obvious way: 6A D 7A C 6A B A (spaced for easy human reading) And if were were particularly concerned about squeezing bytes, we could rotate the last A to the front and have: 7A D 7A C 6A B That's it. In easy scenarios like 60/30/10, we have require less space and less run time with this method. In more complex ones, we clearly gain on run time, since all we need do is compare a pointer and wrap to the front of the array as needed. Depending on the number of queues, we probably use less space, too. If anyone is particularly good at converting recursive algorithms to iterative ones, have at it. I'm sure other, less painful optimizations are possible, too.
| Home | Comments? |