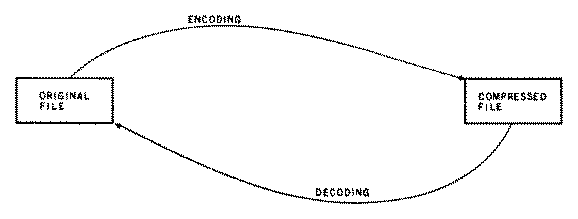
Figure 1. The text compression process.
| Home | Up | Questions? |
A continuing problem on any computer system is storage. There is never enough computer memory for all the information which we wish to store. This is true both for programs in main memory and for the information which reside on peripheral devices.
One solution to this problem is simply to buy more memory. Particularly in the case of storage devices with removable media, such as cassettes, floppies, magnetic tape and even paper tape, additional media can be purchased and used as necessary. But even here economics will eventually limit the amount of storage available.
An alternative approach is to try to make better use of existing storage media. This is where text compression can be of great use. The idea of text compression is to reduce the amount of space needed to store a file by compressing it, making it smaller. Compression is accomplished by changing the way in which the file is represented. The encoding procedure is performed in such a way that it is reversible, that is, it can later be decoded to produce the original uncompressed file. The encoded version of the file is hopefully smaller than the original file, and hence space is saved.
Figure 1. The text compression process.
The cost of this space saving is CPU time. Additional CPU time will be needed to encode and decode the compressed files as they are processed. However, it should be noted that microprocessors are seldom CPU-bound, but more commonly have extra CPU cycles available. In fact, the total execute time of many programs will be less on a compressed file despite its encoded form. This is because the I/O transfer time for a compressed file will be less than the transfer time for an uncompressed file, since there are fewer bits to read or write. Hence, I/O bound programs (like assemblers and loaders) may execute faster on compressed files.
The basic idea of text compression then is to find an encoding for the file to be compressed which takes minimal space. Many algorithms for text compression have been invented and we present some of them here. In general, these algorithms will work for any type of data: numeric, character string, and so on, but for purposes of this paper, we limit ourselves to text, strings of characters. This will include programs, documentation, mailing lists, data, and many other files stored in computers. In fact, object programs too, if considered as simply strings of bytes, can be compressed, although some care must be taken.
Text compression is accomplished by careful selection of the representation of the information in the compressed file. For many small computer systems, ASCII is generally used to represent characters. The main advantage of ASCII is that the representation is standard and easy to define. A major disadvantage is its poor space utilization. ASCII is a 7-bit code while most microprocessors handle 8-bit bytes. Thus, 1 bit out of 8 (12.5%) is wasted simply because a 7-bit character code is used in an 8-bit byte. Further, most control codes are seldom used, and many applications do not need both upper and lower case characters. Thus, another bit can generally be reclaimed with ease providing at least 25% savings in storage space. Many of the algorithms presented here can turn these extra bits into even more savings.
Notice, however, that this approach will require a description somewhere of how the compressed file is represented. This description is commonly the encoding and decoding routines. The savings which result from text compression must be balanced against both the additional CPU time for encoding and decoding and the storage space necessary for the encoding and decoding routines. Also, different types of files may be best encoded by different methods, so several different encoding and decoding routines may be necessary.
A simple approach to compression for text files (but not for object code files) is eliminating blanks which come at the ends of lines, before the carriage return/line feed characters. These are known as trailing blanks. For systems which store lots of assembly language, Basic or Fortran programs, much of each line will be blank. Any trailing blanks can be deleted without changing the meaning of the file.
*** /**.
/***** ******
******* *******
*****'' '******
**/ **'
... /***
**** ******
***** . . ******
****' ****** **/
'' ******/.
****
*
*
/ ./***
.. ./ /*******
/****** */***/'
/**' '** .*/'''
' ** /'
*||
*/
*
|
Figure 2. A file which can benefit from simple text compression techniques. The original file is a 24 by 80 CRT screen image of 1920 characters. Deleting trailing blanks and using tabs set for every 8 columns will reduce the size of this file to 412 characters, a savings of 78.6 per cent.
Tabs can be used to reduce the number of blanks elsewhere in a line. Particularly with block structured programs, such as Algol, Pascal, or PL/I, or with column-oriented languages such as Fortran or assembly language, tabs can be quite effective in text compression. Two varieties of tabbing mechanisms can be used. One is fixed tab stops. In this case, tab stops occur every n columns were n is a system wide constant. Typically n=8, although some studies have shown that n=4 or n=5 will produce additional savings.
The other possiblity is to use variable tab stops. In this case, tab stop positions are selected for each file separately. This would require a decision as to which tab stops are best (i.e., produce the best compression). In addition it would be necessary to indicate with each file what tab settings are to be used. This can easily be done by appending a tab stop dictionary at the head of each file. This dictionary would be used to initialize tables for the decoding routine which would replace each tab with an appropriate number of blanks. This approach would allow different tab settings to be used for different programming languages or data sets.
Trailing blanks and tab mechanisms are mechanisms for compressing strings of multiple blank characters. Some applications may result in strings of identical non-blank characters occurring frequently. For example, picture processing by computer often requires storing long sequences of identical characters. The approach here is to replace a string of n identical characters by the number n and one character, thus saving n-2 characters. The count can be represented as a byte. If the count exceeds 256, it can be output as a count of 256 followed by the character, and then another count and character for the remainder.
Encoding consists of simply counting identical characters until a different one is found and then outputting the count and character. Decoding simply expands each count and character to the appropriate number of characters.
Obviously, n should be greater than 2 most of the time for this approach to succeed. If n were generally 1, this approach would actually double the size of the file! Since this is commonly the case for text files, a more sophisticated approach is generally used.
What we wish to do is to replace sequences of identical characters by a count and character, but to leave single or double characters alone. The problem is how to represent the multiple characters in such a way that the count is not misinterpreted as a character. The common solution is to use an escape sequence. An escape sequence is a means of indicating that a special interpretation should be applied to the following characters. To create an escape sequence, chose any character which is seldom (preferably never) used. For example, in ASCII, one of the control codes or special characters might be used. ASCII even provides an escape character, but if it is being used already for other things, any other character code can be used. Now a sequence of n identical characters would be represented by the escape character, the value n, and the character to be repeated.
$32 $3*$4 /**.@$30 /$5* $6*@$30 $7* $7*@$30 $5*'' '$6*@$31 **/$6 **'@$30 $3.$9 /$3*@$29 $4*$7 $6*@$29 $5* . . $6* @$29 $4*' $6* **/@$31 '' $6*/.@$36 $4* @$43 @$43 *@$43 *@$43 / ./$3*@$30 ..$9 ./ /$7*@$27 /$6*$6 */$3*/'@$26 / **' '**$3 .*/$3'@$26 '$6 ** /'@$35 *$3@$35 */@$36 *@$ 37 @$37 @
Figure 3. The file of Figure 2 can be further compressed by replacing multiple identical characters by an escape sequence. Here an escape sequence is the escape character ($) followed by the number of repetitions and the character to be repeated. This scheme is used only when the repeat count is greater than 2. The count would normally fit into one byte, but here is shown in decimal. The character "@" represents a carriage return/line feed. Only 287 characters are needed to represent the file of Figure 2 using this representation. This reduces the file to 14.9 per cent of its original size.
This allows normal text to be represented normally, except the escape character. The problem which we must now solve is how to represent the escape character if it occurs in the input (uncompressed) text. If we simply copy it to the compressed file, then the decoder will (incorrectly) think that it is the start of an escape sequence and interpret the following two characters as indicating a sequence of identical characters. (This is essentially the same problem that language designers face in trying to represent a quoted string consisting of a quote.) Several approaches to this problem can be used: (a) we can outlaw all occurrences of the escape character, (b) we can replace all escape characters by a special escape sequence, like one with a zero count, or (c), we can replace all escape characters by an escape character, a count of one, and an escape character, treating it as a sequence of length one. Any of these approaches will allow a file to be encoded and decoded easily and correctly.
Notice that in choosing an escape character, we can always use the same one (a system wide constant) or we can select a different one for every file. If we choose a different one for every file, we must make a preliminary pass through the file to look at all characters used and find one which is not used. Then we should append the escape character at the beginning of the file to allow the decoding algorithm to know what character is used as the escape character.
A very common type of file stored in computer systems is a program file. Programs offer great possibilities for text compression because of their stylized form and syntax. The techniques of deleting trailing blanks and using tabs to replace leading blanks can reduce storage requirements considerably. But an even larger gain can be made from keyword replacement.
Most programming languages use a number of keywords or reserved words: in Fortran, such words as INTEGER, FORMAT, CALL and so on; in Basic, such words as LET, READ, PRINT, REM and so on. These words are used throughout these programs and are prime candidates for text compression.
Two techniques are commonly used. First, one can replace each keyword by an escape sequence. The escape sequence would consist of the escape code, followed by a number which indicates which keyword is being used. This has the advantage of allowing a large number of reserved words, up to the number which can be held in one byte, and can be particularly useful for assembly language symbolic opcodes.
An alternative approach is to look through the existing character code for unused character codes. For example, if ASCII is being used, many of the control codes, some of the special characters, and prehaps the lower case characters are not normally used. If 7-bit ASCII is being used with 8-bit bytes, then the extra bit can be used to define 128 new unused codes. These unused codes are paired up with the most frequently occurring reserved words. One code should be reserved for use as an escape or quote character, in case any of the assumedly unused codes should happen to be used in an input file.
For encoding, the input file is scanned for reserved words, and each reserved word is replaced by the appropriate special code. If any of the special codes should show up in the input stream, they are replaced by the two character sequence of the escape code followed by the input character. For decoding, all special codes are replaced by their equivalent keyword, except that any character preceded by an escape code is copied directly to the output, with no replacement.
10 READ A 10 $5 A
20 IF A=0 THEN 110 20 $2 A=0 $6 110
30 IF A>0 THEN 80 30 $2 A>0 $6 80
40 LET B=-A 40 $3 B=-A
50 LET R=SQR(B) 50 $3 R=SQR(B)
60 PRINT A,R," $ " 60 $4 A,R," $$ "
70 GO TO 10 70 $1 10
80 LET R=SQR(A) 80 $3 R=SQR(A)
90 PRINT A,R 90 $4 A,R
100 GO TO 10 100 $1 10
110 END 110 $7
Figure 4. Here a Basic program has been compressed by keyword replacement. The keywords (1) GO TO, (2) IF, (3) LET, (4) PRINT, (5) READ, (6) THEN, and (7) END have been replaced by an escape sequence consisting of an escape character ($) followed by a keyword number. Notice that the escape character occurred within the original input program, and was replaced by a special escape sequence ($$). In actual use, all delimiting blanks around keywords would also be subsumed into the keyword. Thus, line 10 would be 10$5A, and $5 would mean " READ ".
At this point, a problem may become apparent. Note that the keywords for any particular language are fixed and relatively small in number, but that the keywords vary from language to language. Hence, the appropriate correspondence between special codes and reserved words may vary greatly. In one-language systems (such as those which offer only Basic) this is not a problem, but more general systems need to consider this problem.
Several solutions are available. First, one can simply use separate encoding and decoding routines for each language, leaving it to the programmer to use the appropriate one. Second, one can tag each compressed file with a byte which indicates if this is a Basic-compressed-file, or a Fortran-compressed-file, or a type-X-compressed-file. Then the encoder must either be told how to encode the file or be able to guess (or compute) that this is a Fortran or Basic or type-X file and apply the appropriate compression algorithm. The compressed file is tagged as it is encoded. The decoder looks at the tag and uses the appropriate decoding scheme.
A third approach is more general, but potentially more expensive. Notice that the differences between the encoding and decoding algorithms for the different types of files is simply the table of pairings between keywords and character codes. So another approach is to prefix each compressed file with a dictionary of character code/reserved word pairs. The dictionary explains the meanings of the special character codes by indicating the reserved words which they stand for.
The idea of appending an abbreviation dictionary to the front of a compressed file opens the way to using the keyword replacement scheme for more general files. The idea is quite simple. Pick out those sequences of characters which occur most frequently in a file and replace them with a special character code. To allow decoding, we append a dictionary at the beginning of each file to show which special character codes correspond to which replaced character strings. This approach can yield very good text compression, especially for programs or natural language text, since keywords, variable names and some words (like "the", "and", and so on) are used very frequently.
Dictionary:
$A "the"
$B "text compression"
$C "computer"
...
Text:
This paper is concerned with $A use of $B in $C
systems, where $A amount of $C storage is limited.
...
Figure 5. Text compression by substring replacement. Substrings are replaced by abbreviation codes (here we use escape sequences). The dictionary at the beginning of the file defines the meanings of the abbreviations.
But there are some problems with this approach also. The major problem is selecting the character strings to be abbreviated. With programs written in particular languages, keywords occur frequently and so were a safe bet for substitution, but what are appropriate character strings for general replacement? These can only be determined by examining the file, since the appropriate strings will vary from file to file.
The objective, of course, is to realize the greatest savings. Here we are limited mainly by the number of codes available for substitution. If we use unused codes in the existing character set, we are limited to from ten to fifty abbreviation codes, typically. If we extend the character set (say by using 8-bit codes with 7-bit ASCII) then we may have as many as 128 codes available. Using an escape sequence may provide up to 256, but at a cost of at least two characters per abbreviation. In all cases, the number of codes available will always be limited, say m. Thus we need to pick those m strings for abbreviation which will result in the greatest savings.
Notice that we do not always want to pick merely the most frequently occurring m strings. Consider the two strings "to" and "text compression". If "to" occurs 100 times and "text compression" only 15 times which should we replace? Replacing the two character sequence "to" by a single abbreviation code will save only one character (assuming one byte abbreviation codes) per occurrence, or a total of 100 characters. Replacing the sixteen character "text compression" will save 15 characters per occurrence, or 225 characters total. Thus, in general we wish to replace that character sequence whose product of length and frequency is greatest.
The encoding problem then is to find the m sequences whose length-frequency product is greatest, replace all occurrences of them with the m abbreviation codes and append the abbreviation dictionary at the front of the compressed file. The decoding problem is merely to read in the abbreviation dictionary, and then replace all abbreviation codes by the appropriate character sequence.
The only real difficulty is finding the m sequences to be abbreviated. No really good solution to this problem is known. The best solution which I have seen works like this. First make one pass through the file to compute the most frequently occurring pairs. There should probably be no more than 2500 of these and probably much fewer. Compute the frequency of these pairs and keep only the m or 2m most frequent. Now consider that any sequence of length three both begins and ends with a subsequence of length two, and these two subsequences of length two must be at least as frequent as the length three sequence. That is, if there are 23 occurrences of "abc", then there must be at least 23 "ab" and at last 23 "bc". Thus, we can now make another pass through the file counting the frequency of subsequences of length 3, but limiting ourselves to those sequences which begin and end with subsequences of length two which are also frequent. Then we can make another pass for length four (limiting the sequences to those with frequent length three subsequences), and another pass for length five, and so on, until we decide to quit. We can quit either when our last pass has produced no new sequences whose frequency-length product exceeds the previous set, or after a fixed number of passes.
All of the above schemes for text compression are similar in the sense that they confine themselves to working within the given character code and byte structure. Even more savings can result from recoding the character code representation itself. Almost all character code representations use a fixed code size: 6 bits for BCD, 7 bits for ASCII and 8 bits for EBCDIC. This can be very wasteful of space.
Consider the simple problem of encoding the four characters:
"A", "B", "C", and "D". If we use a fixed code size, then we could
encode each character with 2 bits, as follows:
A 00
B 01
C 10
D 11
But suppose that the letter "A" occurs 50% of the time in the text,
"B" occurs 25% and "C" and "D" split the remaining 25% equally. Then
the following variable length character code will produce a
shorter average text length.
A 0
B 10
C 110
D 111
To compute the average text length consider that out of n characters,
n/2 will be "A" which requires only one bit, n/4 will be "B" for
2 bits each and the remaining n/4 will be "C" or "D" for 3 bits each.
Thus the total number of bits to represent n characters is,
1*n/2 + 2*n/4 + 3*n/4 = 1.75n
Comparing this with the 2n bits needed for the fixed length
code, we see that we have saved 12.5% of the total file size.
Variable length coding and decoding is somewhat more complex
than fixed length coding, but not really difficult. it involves much more
bit manipulation. To encode a string like "ABAABCDAB", we simply
concatenate the bit representations of each character,
packing across byte boundaries as necessary.
A B A A B C D A B
0 10 0 0 10 110 111 0 10
To decode, we must scan from left to right, looking at each bit. For the string 01001100, we notice that the first bit is a 0. Only "A" starts with 0, so our first character is an "A". The next bit is a 1, so it could be a "B", "C" or "D", but looking at the next bit we see that the next character must be a "B". We remove the two bits for the "B", and continue. The next bit is a 0, so the next character is an "A". The following bit is a 1, signifying either a "B", "C", or "D". The next bit is a 1, signifying a "C" or "D". Finally the next bit indicates a "C". The last character is an "A". So our decoded text is "ABACA".
Computer stored text files can benefit greatly from Huffman coding. Huffman coding can be used anytime the probabilities of the character codes are not equal. In fact, the more unequal the probabilities the better the compression with a Huffman coding. Looking at a table of frequencies of the letters in English, we can see that they are quite unequal, and hence can be compressed nicely with Huffman coding.
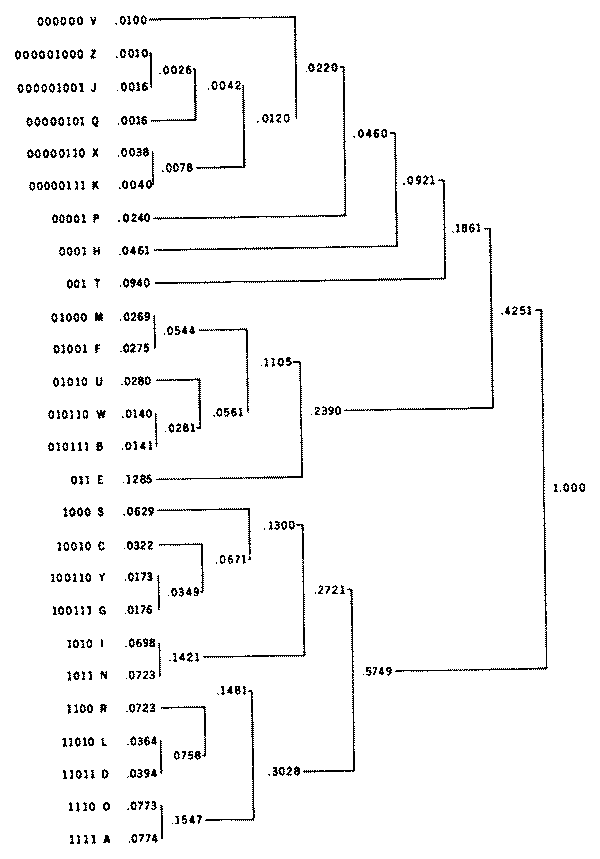
Figure 6. A Huffman code for the letters of the English language is based upon the probabilities (frequencies) of the letters in English. The code lengths vary from 9 bits (for infrequent letters like "z" and "j") to only 3 bits (for "e" and "t"). The average length is 4.1885 bits per letter. Five bits would be necessary for a fixed length code, a savings of 16%.
To construct a Huffman code, a very simple algorithm is used. first, it is necessary to compute the probabilities of the characters to be encoded. This requires one pass through some sample text, a part of a file, the whole file or several files, as desired, counting the occurrences of different characters. Then we need to sort the characters according to their frequency. Take the two least frequently occurring characters, and combine them into a "super character" whose frequency is the sum of the two individual characters. The code for each of the two characters will be the code for the "super character" followed by a 0 for one character and a 1 for the other. Now delete the two least frequently used characters from the list and insert the new "super character" into the list at the appropriate place for its frequency. Continue this process until all characters and "super characters" are combined into one "super character". The result is a Huffman code of minimal average code length. The Huffman code may best be seen as a binary tree with the terminal nodes (leaves) being the characters which are encoded.
Huffman coding can be quite successful in text compression, in extreme cases reducing the size of a file more than half. The basic technique can be improved upon in a number of ways. For example, pairs of characters, rather than single characters, can be used as the basis of the encoding. This requires a much larger table of character frequencies, since now we need to compute the frequencies of character pairs, and larger tables of character pair-Huffman code associations, but can result in greater savings.
Another possibility is to use conditional Huffman coding. The objective here is to utilize the fact that the probability (frequency) of a character will vary depending upon what character proceeds it. For example, compare the probability of a "u" following a "Q" (nearly 1) to the probability of a "u" following a "u" (nearly 0). So an optimal encoding should use a very short code for "u" which follow "Q" and can use a very long code for "u" which follow "u". The encoding algorithm is to compute the frequency with which each character follows each other character. Then a separate Huffman code is computed for the characters which follow each character. The encoding scheme remembers the last character encoded and uses that to select the code to be used for the next character. The decoding algorithm must also remember the last character decoded to be able to select the correct decoding algorithm.
Huffman codes are really quite simple, but they can be made more sophisticated to achieve increased text compression. However, even with simple Huffman codes, some problems can arise. First, notice that Huffman encoding and decoding both involve a great deal of bit manipulation which can be very slow to program. Second, the best compression is achieved if a Huffman code can take advantage of the unequal frequencies of characters in a file, but these will differ from file to file. Thus a separate encoding may be best for each file. This can be done by appending the code at the front of the file (as with the dictionaries used for abbreviations) but this increases the size of the file (significantly for small files).
Third, the variable length code nature of Huffman coding can make them extremely vulnerable to transmission or storage errors. In a fixed length code, if one bit is changed, only that one character is affected, while with Huffman codes, both that character and all succeeding characters may be decoded incorrectly, because of a mistake in the assumed length of the incorrect character. (A similar problem would happen to a fixed length code if a bit were dropped or added.) Thus, for safety, it is necessary to add error detection and correction redundancy back into the file, increasing its size.
Still there are environments where Huffman coding could be quite useful. Consider a word-processing system storing files on a low-speed serial device such as a cassette. Since the system is special purpose, one can compute the expected frequencies of English characters and use one Huffman code for all files. Encoding and decoding would be done automatically by the tape driver routines. Alternatively the encoding and decoding could even be built into the tape drive hardware itself, as special-purpose logic or a small processor with a ROM encoding/decoding table. This encoding/decoding approach would be totally transparent to the user. The only effect on the user would be the ability to store a larger, but variable number of "characters" on a fixed amount of tape.
The amount of storage space available in a computer system, particularly small computer systems will always be limited, either physically or economically. Often however the amount of storage space which is necessary to store some information can be greatly reduced by some simple text compression techniques, such as we have presented here. Each of the techniques presented can save some space in many files. And many of the techniques can be used one after another to achieve more and more compression. Text compression can be a simple and effective method of increasing the amount of storage available in exchange for some CPU cycles.
1111 A .0774 000000 V .0100
010111 B .0141 000001000 Z .0010
10010 C .0322 000001001 J .0016
11011 D .0394 00000101 Q .0016
011 E .1285 00000110 X .0038
01001 F .0275 00000111 K .0040
100111 G .0176 00001 P .0240
0001 H .0461 0001 H .0461
1010 I .0698 001 T .0940
000001001 J .0016 01000 M .0269
00000111 K .0040 01001 F .0275
11010 L .0364 01010 U .0280
01000 M .0269 010110 W .0140
1011 N .0723 010111 B .0141
1110 O .0773 011 E .1285
00001 P .0240 1000 S .0629
00000101 Q .0016 10010 C .0322
1100 R .0723 100110 Y .0173
1000 S .0629 100111 G .0176
001 T .0940 1010 I .0698
01010 U .0280 1011 N .0723
000000 V .0100 1100 R .0723
010110 W .0140 11010 L .0364
00000110 X .0038 11011 D .0394
100110 Y .0173 1110 O .0773
000001000 Z .0010 1111 A .0774
The Huffman codes for the letters from Figure 6, for additional clarity.
| Home | Comments? |