Inclusion of Makefiles
| Home | Up | Questions? |
This note is an attempt to record the useful information that we have acquired while porting the K42 operating system to the X86-64 processor.
The K42 group is developing a new high performance, general-purpose operating system kernel for cache-coherent multiprocessors. We are targeting next generation servers ranging from small-scale multiprocessors (which we expect will become ubiquitous) to very large-scale non-symmetric multiprocessors that are becoming increasingly important in both commercial and technical environments. The K42 operating system is designed to be compatible with the Linux operating system. K42 currently runs on PowerPC and MIPS systems (both native and using SimOS).
One of the processors which we expect to be widespread is the X86-64 architecture. It is a clean extension of the common "x86" architecture to 64 bits. The x86 processor registers are extended to 64 bits, and the number of registers is increased to 16. In addition, memory addresses are extended to 64-bits, including a 64-bit instruction pointer (rip) and stack pointer (rsp). A compatibility mode supports the previous 32-bit architecture.
Our task was to port K42 to the X86-64 architecture.
The first problem is to get access to the K42 source. The K42 source tree is stored in CVS, and available from the CVS server on rios1.watson.ibm.com. We are able to access the entire tree using
CVSROOT=:pserver:peterson@rios1.watson.ibm.com:/u/kitchawa/cvsrootGetting a copy of the entire K42 source is then
cvs co kitchsrc
The source tree is designed to contain both source code and documentation, as well as the tools and structure to compile and link (build) the source code.
The majority of documentation in K42 is contained in sgml files in a subdirectory called doc in each source directory. There are a series of top-level documents that provide help with getting started on the system (in the kitchsrc/doc directory). There is a Makefile in each doc directory to make documentation at that level. Executing a make world from the top-level doc directory will build all HTML documentation throughout the system (other choices are make world_ps for postscript and make world_all for both HTML and postscript). For convenience, pointers to many of the HTML files are built into a file called docPointers in the doc directory. There are a series of technical white papers in the doc/white-papers directory. These can also be found on the K42 home page (http://www-stage.watson.ibm.com/K42/index.html).
Production of the documentation HTML (or postscript) files from the source SGML files is designed bo be done on a Linux system. It uses several tools, including the following RPMs:
sgml-common-0.1-10 sgml-tools-1.0.9-8 jadetex-2.7-4 openjade-1.3-6 tetex-fonts-1.0.7-7 tetex-1.0.7-7 tetex-*-1.0.7-7You can probably find these RPMs at http://rpmfind.net (in particular http://rpmfind.net/linux/RPM/).
File names and counts
692 *.H -- C++ header file
654 *.C -- C++ code file
238 Makefile
184 *.sgml -- SGML documentation
143 *.c -- c code file
115 *.h -- c header file
72 Make.arch
56 *.ent
47 *.S -- assembly language file
41 *.fig -- documentation figure (xfig)
36 *.tex -- TeX file
34 *.eps -- encapsulated postscript
28 *.sh -- shell script
22 *.src
20 *.java -- java source
11 *.gplt
11 *.data
11 *.awk
10 Make.files
10 *.raw
10 *.idraw
7 *.ps
4 profile
4 *.y
4 *.sty
4 *.s
4 *.old
4 *.conf
3 TODO
3 *.scr
3 *.lds
3 *.html
3 *.bib
...
The source code should be fairly consistent in style, since the team has an agreed upon coding style. In general, code should be ANSI C++ specifically for the gnu C++ compiler. We are in the process of transitioning from GCC 2.0 to GCC 3.0, so the code should compile on both.
K42 was designed to be ported to multiple architectures, initially powerpc and mips64. We added the amd64 and have partially completed the generic64 architectures. These TARGET architectures have architecture specific code for a number of functions, such as the low-level hardware operations to support CPU scheduling and memory management.
Architecture specific changes to the build process (defining architecture specific files to compile, for example), are put in Make.arch files. These are included in the corresponding architecture independent Makefiles. Thus, the kitchsrc/os/kernel/mem/Makefile will include one of mem/arch/amd64/Make.arch, mem/arch/generic64/Make.arch, mem/arch/mips64/Make.arch, or mem/arch/powerpc/Make.arch, depending upon the target architecture being specified.
Architecture specific code is kept under an arch directory in the source tree. Each arch directory has a subdirectory for the architecture specific code for each supported architecture. Porting K42 to a new architecture will involve creating and populating a set of new directories under arch directories.
The generic64 port is designed to help with the port to a new architecture. The idea of the generic64 port is that it defines the interface between the architecture independent portion of K42 (most of the code) and the architecture dependent portion (which needs to be created for each new port). The objective is to provide a clear definition of what needs to be provided for each port.
To create a new port, in theory, one needs only to define a new name for your port, copy the generic64 files, changing all references to generic64 to the name of the new port, and then fill in the contents of the procedures and methods in these files. The size of this task can be approximated by the number of files in the generic64 directories:
39 *.H
27 *.C
17 Make.arch
13 Makefile
6 *.c
5 *.h
3 *.sgml
2 *.src
1 *.ent
1 *.awk
Many of the architecture specific directories are similar across the various ports -- examining the other ports can be very helpful in defining a new port.
The K42 build process is based upon standard GNU make. Each directory, starting at the top, includes a Makefile. This Makefile defines a set of make targets which can be used to build the entire system. In general, make in one directory will recursively invoke itself on its subdirectories to accomplish its task.
The objective of the build process is to produce a set of binaries. The most important is boot_image -- the bootable image of the K42 kernel. In addition, there are a larger set of programs and servers which are created to be run on K42.
The build process is designed to allow multiple simultaneous builds for different target architectures. The target architecture is defined by the ARCHS environment or make variable. For example, building the powerpc K42 system involves:
ARCHS=powerpc make or make ARCHS=powerpcwhile building the amd64 K42 system is:
ARCHS=amd64 make or make ARCHS=amd64
The ARCHS is used to define the TARGET_MACHINE make variable. This can be used to test in the makefiles for a particular target architecture. In addition it is passed to C and C++ as a preprocessor variable, which can be used for #ifdef's. The structure of K42 has been designed to minimize the need for platform specific #ifdef's -- there are only 18 such tests for TARGET_generic64.
A separate, but related make variable is the PLATFORM that is supporting the build process itself. K42 is meant to be cross-compiled -- that is, compiled on one platform for another target. Specifically, we normally build powerpc K42 on AIX, mips64 K42 on IRIX, and amd64 on Linux; generic64 K42 should build on any platform. The platform is determined by the build process as it runs and does not need to be explicitly set. By default, if no TARGET_MACHINE is specified (with the ARCHS environment variable), the build environment picks the TARGET_MACHINE base on the build platform.
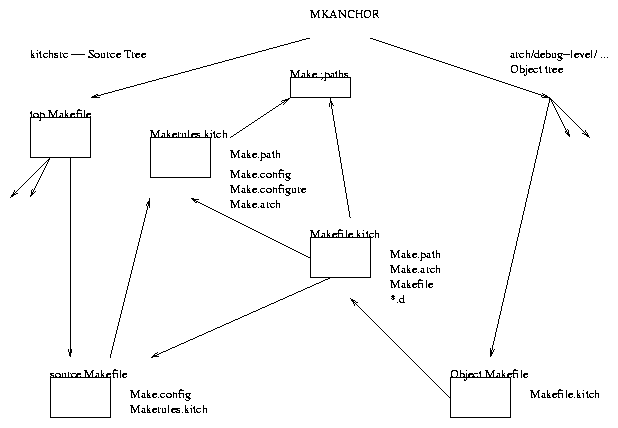
The K42 build divides into three directory trees: the source (kitchsrc), the install (install), and the object. The object tree is defined by the Target architecture and the debug level (fullDeb, partDeb, noDeb). For example, for the PowerPC architecture and the highest level of debugging, the object tree is powerpc/fullDeb/... For the mips architecture, and no debugging, the object tree is mips64/noDeb. The purpose of this structure is to allow builds for multiple target architectures from the same source tree at the same time.
Overall, the source tree is the original input to the build process. The source tree is kept in CVS. Everything can be built from the source tree (with the exception of the build tool chain -- gmake, gcc, ...).
The install tree is used to store the intermediate results of the build; results which may be used by other parts of the build, such as header files (install/include) and libraries (install/lib).
The object tree stores the temporary files that are generated as the result of a build -- the object files (*.o) and such. The object tree is a parallel structure to the source tree -- for each source directory in the source tree, a directory of the same name is in the object tree. The result of compiling a source file, from the source tree, results in an object file in the parallel object tree.
The top-level makefile in the source directory normally drives everything. There are two main commands at this level: full_snapshot and fast_snapshot. full_snapshot is a full build; fast_snapshot is used for incremental builds.
A full build consists of a number of separate, sequential steps. Each step traverses the entire source tree, with each makefile invoking make on each of its subdirectories.
To provide uniformity in the way that the build is performed in each subdirectory, most of the build is controlled by a common set of rules. These rules are defined in kitchsrc/tools/lib/Makerules.kitch which is "included" into each Makefile.
Each Makefile also includes its own local Make.config file. The Make.config file defines several makefile variables (_CWD, MKANCHOR, MKKITCHTOP) which are used in the build process. The Make.config files are automatically generated early in the full build (by the "make configure_sesame" command).
Makerules.kitch itself "includes" several other files to support the build process:
Makerules.kitch mainly defines all the rules that drive the build process. This allows the Makefiles in the various directories to consist mainly of the definition of makefile variables which then activate the rules in Makerules.kitch. For example, the definition of SUBDIRS will automatically mean that the subdirectories are recursively called by make for the standard commands: clean, install_includes, and so on.
Each directory in the object tree has two basic files: Makefile and Make.config. Both of these files are automatically generated during the "make configure_sesame" step of a full build. The Makefile defines several variables which identify it and the parameters of the build (the TARGET_MACHINE (powerpc, mips64, amd64) and OPTIMIZATION (fullDeb, partDeb, noDeb), as well as the path to the parallel source file directory (SRC_DIR_PATH), and the top of the build tree (MKANCHOR and MKKITCHTOP). The Make.config file in the object tree is identical to the Make.config file in the source tree.
The Makefile in the object tree includes Makefile.kitch. This "generic" object tree Makefile includes Make.paths, Make.arch, and all the generated dependency files (*.d). In addition it includes the Makefile for this object directory from the corresponding source tree. Doing so provides all the information about the files to be compiled, and so on, that is included in the source tree Makefile, but leaves us still in the object directory. VPATH is used to allow make to find the source files (in the source tree) for compilation.
VPATH = $(SRC_DIR_PATH):$(SRC_DIR_PATH)arch/$(TARGET_MACHINE)In addition, of course, including the source Makefile also includes Makerules.kitch, which provides all the rules for the build.
Of particular importance to porting K42 to a new platform is Make.paths which is in the top-most directory, kitchsrc. All makefiles eventually include Make.paths. All build tools (such as the compiler, assembler, linker, and so on) are referred to by make variable names. The value of that variable is defined in Make.paths. The actual tool name is never used directly, but always thru the make variable, allowing a change to Make.paths to change the tool used. For example, rather than using "awk" directly, we use $(AWK), where AWK is defined (by default) to be "awk" in Make.paths. This allows one change to Make.paths to replace awk with "nawk", or to prepend a path which finds awk in a different directory.
If Make.paths does not exists (and it does not exist in CVS), it is made by copying MakePaths.proto (which is in CVS). A common practice is to copy MakePaths.proto to Make.paths and then edit Make.paths to provide local definitions for your build process.
A large part of Make.paths is a section that defines the build tools for each target. For example, TARGET_CC is the C compiler that produces code for the target. This may will differ from HOST_CC unless we are self-hosting. HOST_CC would be used to compile build tools, which will run on the host (build) platform (AIX, IRIX, Linux), rather than on the target K42 system.
Make.paths defines a set of default commands and directories. A platform and target specific part of Make.paths may then override the default for a particular Target and/or Platform. You will need to define these values to match the build tools for your port. In general, we assume GNU tools, particularly gcc as the compiler, and Unix/Linux types of commands (cmp, mv, rm, sed, sort, cat, awk, echo, ...).
In addition to the basic build tools, it will be necessary to provide various additional standard libraries and include files. These are put under k42-packages, and include libc.a and libpthread.a. The location of these packages is defined by the make variable K42_PKGDIR which is based on the target specific lines in Make.paths.
We have had continuing problems with routines being defined both in libc.a and in the K42 sources, particularly, memcmp, strrchr, and xlocale. These have been removed from the copy of libc.a in k42-packages for our build.
And we are working towards needing a copy of the Linux source tree for your platform. The Linux source tree is defined by the environment variable LINUXSRCROOT.
An important part of the build process is the stubgen program. K42 consists of a number of servers which support methods on objects. Communication between the clients and the servers is done by a PPC_CALL -- effectively a remote method call on an object. The code to implement this is generated by stubgen. The C++ header files are annotated by keywords describing the parameters for methods: __in, __out, __inout, __inbuf, __outbuf, and __XHANDLE. For normal compilation, these are #defined appropriately, but stubgen uses them to determine how values should be marshalled and demarshalled for the PPC_CALL.
The mechanisms in stubgen are very sensitive to the way the vtable is laid out for C++ (version 2 or version 3) and the loader file format (xcoff or elf). An important part of the correctness of a port is getting the stubgen generated code correct.
One problem that will need to be addressed, once the code is written and the build is producing a boot image is getting the boot image to boot the machine (or simulator). Several possibilities can be used:
Possibly the most difficult part of the port will be debugging the code once it is written. The difficulty is that most of the tools that one uses to debug programs run as application programs. There are some approaches which may help.
The most basic debugging tool must be your hardware or simulator. An ability to single-step thru the basic initial boot code and examine registers can be very useful. We found that single stepping, breakpoints, and examining registers and memory were very useful.
One approach we used was to execute to a breakpoint around the problem area. We then single-stepped for thousands of instructions, capturing the program counter and instructions thru logging the Xterm window that we were executing in. This log of execution was then post-processed to substitute labels for addresses, allowing us to see the sequence of function and method calls.
An alternative to the low level simulator debugging was the use of print statements. There are three levels of print statements used in the code:
An attempt was made to annotate the entry and exit of every procedure, function and method, by modifying a copy of the source code. This was helpful in verifying the early execution of the kernel, but quickly produces too much output to be manually useful.
Phillipe uses gdb to debug the kernel, and servers in user mode. The advanatage of gdb is that it allows tracing and breakpoints at the source level. gdb works by a special connection between gdb and between the simulator, letting it control execution and query and set registers and memory.
As code has been written, many preconditions and postconditions were assumed by the authors. These were captured in a variety of assertion statements added to the code. Assertions come in two basic flavors: temporary (used only for the debugging versions; compiled out of the non-debug versions), and permanent (always compiled in). In the following, EX is an assertion expression (a boolean expression), MSG is a message to print (including optional arguments) using err_printf, and STMT is a sequence of C statements.
Permanent: passertSilent(EX) - breakpoint if EX is false passert(EX, STMT) - if EX is false execute STMT and breakpoint passertMsg(EX, MSG)- if EX is false print MSG and breakpoint passertWrn(EX, MSG)- if EX is false print MSG, no breakpoint Temporary: tassertSilent(EX) - breakpoint if EX is false tassert(EX, STMT) - if EX is false execute STMT and breakpoint tassertMsg(EX, MSG)- if EX is false print MSG and breakpoint tassertWrn(EX, MSG)- if EX is false print MSG, no breakpoint
With this scheme the prefix always determines the conditions under which the assertion is compiled in and the suffix determines the effects of the assertion.
As you can see from the following counts, tassert is more common that passert.
361 passert
22 passertMsg
4 passertWrn
2067 tassert
127 tassertMsg
135 tassertSilent
206 tassertWrn
You may find a reference to wassert, an earlier form of assert macro
that should have been converted to tassertWrn.
Once the system boots, it will execute KernelInit() and then KernelInitPhase2, which ends by calling choose_test(). choose_test prompts for input from the console to select a test. A '?' will list the available tests. The regression tests ('r') would be the important one.
Some values of the regression test may reasonably vary from system to system; for example, memory addresses for different ports. These values should be printed with a '0x' prefix. Ignoring these values, the regression tests between different ports should be the same.
Once the system compiles, and particularly once it can run the regression test, it can be set up to run automatically under the "knightly" script. Knightly is designed to be run under a cron job -- for example, every night. It is a check that any changes made to the system still leave the basic functionality that is needed for the system to compile, boot, and run the regression tests. The knightly script has many options, but in normal mode will first check all the sources out CVS, compile them, boot them on the simulator, and run the regression test. Under normal use, it compiles all three debugging levels: fullDeb, partDeb, noDeb. As a result it needs significant disk space; for the amd64, about 6 Gigabytes of disk space are needed.
There is work afoot that changes the way that K42 interacts with Linux. The idea is to have K42 be a platform for Linux, providing the "hardware" on which Linux runs. This creates a new set of requirements for getting K42 to work; specifically, Linux will need to be working too.
To run the standard GNU/Linux user commands (like ls, cat, ...) on K42, they are re-linked with a K42 specific version of glibc which makes K42 system calls, instead of Linux system calls.
| Home | Comments? |