| Home | Up | Questions? |
This paper addresses a purely software-based solution to the multiprocessor cache coherence problem by structuring the operating system to provide for the coherence of its own data while exporting coherent memory to user processes.
A processor-based model is defined for providing coherence at a page level by performing traditionally hardware-based coherence protocols through the page fault and interprocessor communication facilities. The processor-based model is used by the operating system to export coherent, sequentially consistent memory to user processes.
A thread-based model is defined for the operating system code itself that allows a high level of parallelism between cooperating threads. Techniques are described for structuring an operating system based on this model. Included are the categorization of data types, their allocation requirements relative to memory block boundaries, their memory block separation requirements, and their potential packing into memory blocks.
A technique is presented which was developed to detect coherence ``violations'' in a testing environment requiring no special hardware support other than the standard address translation mechanism. This technique can expose coherence violations even when executed on a uniprocessor. A multiprocessor test platform is needed for validating code which is only exercised when executing on a multiprocessor.
This paper covers what is believed to be the first implementation of an operating system on a non-coherent machine by using these principles, techniques, and testing tools to restructure Mach 3.0 for execution on the prototype for the IBM Shared Memory System POWER/4 TM, a Shared Memory Cluster. This allows the system to appear as a single 4-way Symmetric Multiprocessor instead of a four node cluster. Benchmark results show that this solution scales well on the four CPU prototype with a throughput increase of up to 3.9 times that of a single processor system.
Most computer systems have only one processor. This limits the size of computing problems that can be solved on these systems, however. As a result, new computing systems are being designed with multiple processors.
The simplest way to create a multi-processor (MP) system is to take an existing set of uniprocessors and tie them together with a high speed network, forming a cluster of processors. Messages can be passed back and forth across the network to allow programs to communicate and solve larger problems.
While it is easy to create a cluster, it is not as easy to use it. Simple clusters run a separate copy of the operating system on each processor, creating N different computer systems to deal with. The user and system administrator are faced with N different sets of devices, file systems, and so on, while what is desired is a single system image. Providing a complete single system image on a cluster of systems is a difficult task that is still being worked on. Existing operating systems must be substantially modified to work in a cluster as part of a single system image.
Application programs too must be changed to work in a cluster. Problems must be broken up into multiple pieces, for the multiple processors, and communication between the processors must be explicitly programmed as messages between the processors.
An alternative multiprocessor architecture is Symmetric Multiprocessing (SMP). An SMP modifies the design of a uniprocessor to provide multiple processors, each of which has the same access to memory and all I/O devices. Shared access to memory allows both operating systems and applications to be written which communicate by simply loading and storing in shared memory, a more familiar model of computing than message passing for most programmers. Since all system resources are available to all processors, a single system image can be easily provided.
Problems do arise when working with SMP systems, however. In particular, since multiple processors may simultaneously attempt to modify data, it is necessary to provide ways to maintain data integrity. This is normally accomplished by allowing only one processor at a time (mutual exclusion) to execute code (a critical section) that manipulates a specific set of shared variables. Locks (synchronization variables) which are locked before (the entry section) and unlocked after (the exit section) a critical section of code are one approach to preventing data from being used by two different processors at the same time. Algorithms must be modified to properly protect shared data. The number and style of locking can make a major difference in the degree of parallelism.
Another form of this same sort of problem is the cache coherence problem. High performance processors maintain, in hardware, caches of recently used instructions and data. When a data item is first referenced, the memory block (typically 16 to 256 bytes) containing it is loaded into the cache. Subsequent references to data items are satisfied from the cache. The cache coherence (CC) problem occurs when two or more processors, using their private caches, share changeable data. A data integrity problem can occur when two processors modify different variables that reside in the same memory block; regardless of the order in which the cached blocks are copied back to real memory, the correct value of both variables will not be reflected. A data staleness problem results from a processor's subsequent access to its cache for the value of a variable which has been modified by others.
Solutions to the CC problem are categorized by models which describe how, when, and for which shared data items coherence is provided.
Most SMPs provide strongly ordered memory access by special purpose hardware. The hardware examines all memory accesses and signals processors to flush and invalidate their local caches as necessary to maintain cache coherence. The hardware for cache coherence limits the scalability of the SMP architecture.
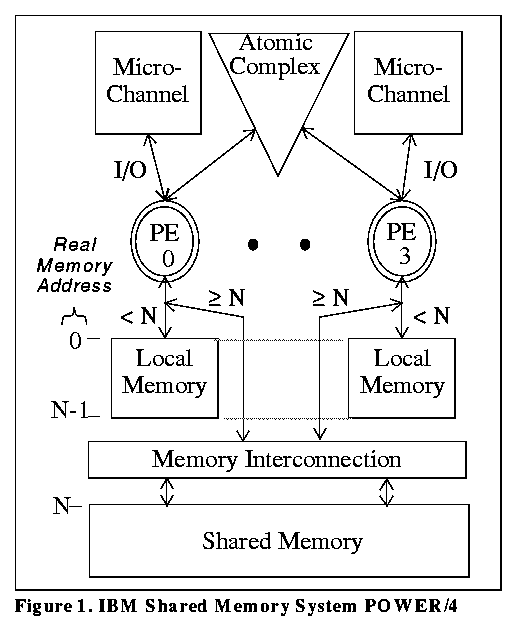
The Shared Memory Cluster is emerging as an architectural base for Massively Parallel Processing (MPP) systems. SMCs are multiprocessors typified by access to shared memory which is not kept cache coherent by hardware. The processing elements (PEs) can be off-the-shelf uniprocessor chips with private caches that buffer load/store access to both private memory and a common pool of shared memory. This pool can be centralized as in the IBM Shared Memory System POWER/4 TM or distributed as in the Convex SPP.
The IBM Shared Memory System POWER/4 [IBM93] combines four IBM POWER RISC processors into a single system. Each processor has private access to one local memory card (from 16 to 128 MB) and an IBM Micro Channel I/O Bus. In addition, each processor has shared access to up to 896 MB of shared memory (without cache coherence controls) and an Atomic Complex that provides semaphore operations for serialization and interprocessor communications. Figure 1 shows the system overview.
Figure 1. IBM Shared Memory System POWER/4
Each PE in the POWER/4 has an 8KB instruction cache and a 32KB data cache. The data cache is four-way set associative with 512 cache blocks of 64 bytes each. The cache management operations are those provided by the unmodified PEs. These include instructions to:
The hardware selected for this project was a prototype for the IBM Shared Memory System POWER/4. Unfortunately there are currently no operating system implementations for shared memory clusters. The choices were to write a new one, or modify an existing one.
In particular, the operating system must be able to run on hardware which supports an unordered model of access to shared memory, but must provide a strongly ordered model for user programs. While it may be possible to rewrite all applications to run on an unordered model, it would clearly be advantageous to be able to continue running all existing applications, which were written assuming a strongly ordered model of memory. Let us look first at how we can provide a strongly ordered model of memory for user applications with hardware which does not provide cache coherence.
Coherence of memory accesses requires that all accesses to shared memory always retrieve the result of the latest write to that memory. When caches are being used, the following requirements will provide memory coherence.
Coherence Conditions:
The Coherence Conditions require that accesses to shared memory on one processor change the way in which memory is cached and accessed by other processors. For example, if processor A is reading a shared memory block and processor B attempts to write to that memory block, we must prevent processor A from reading until the write from processor B is stored back from processor B's cache into shared memory. Plus processor A's cache must be invalidated to force it to get a new copy of the modified data from memory.
We can use the page table as a way to control the access of user programs to shared memory. On the POWER/4, 64 memory blocks (64 bytes each) are wholly contained in each page (4KB). Each page has an associated state for each processor: None, Read Only (R/O), and Read/Write (R/W). Figure 2 shows the per-processor state diagram for each page
Figure 2. Per-Processor Page Access State Diagram for User Coherence
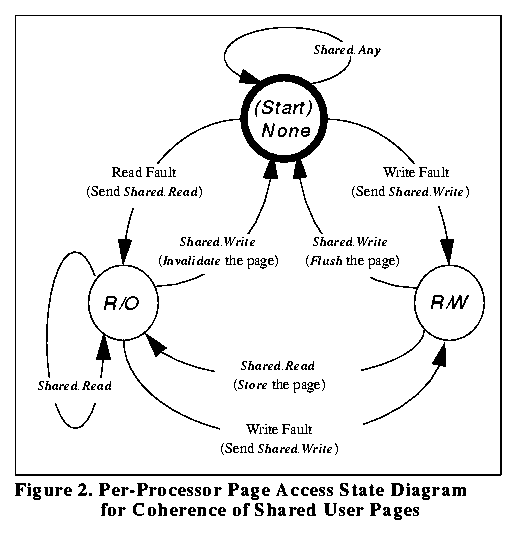
Shared.Read and Shared.Write are synchronous requests that are broadcast to all other processors. Processors that receive a Shared.Read notification for a page they have mapped as R/W must store the page's memory blocks and reduce all access on their processor to R/O before replying. A processor that receives a Shared.Write must flush the page if it is mapped R/W, then reduce all access to None before replying.
Thus in our example, both processor A and processor B initially have no access to the shared data. When processor A attempts to read the data, a page fault occurs. The operating system sends a Shared.Read request to all other processors, changes its page table to allow read access and resumes execution of the user program on processor A. Later when processor B tries to write into the shared data, a page fault occurs on processor B. The operating system sends a Shared.Write request to all processors. Processor A invalidates its cache copy of the shared data, and changes its page table to deny further access to the shared data. Processor B waits for the reply from processor A and then changes its page table to allow write access to the shared data. If processor A reads the data again, it will again fault, sending a Shared.Read request to processor B which will store the shared data from its cache into memory, reducing the allowed access in its page table to read access. Processor A waits for the reply from processor B and then changes its page table to also allow read access to the shared data.
Providing cache coherence via the page protection mechanism has two drawbacks compared to hardware solutions (which are memory block-based). First the latency for software page fault handling is higher than the latency for hardware coherence schemes because of the context switching required for handling the page/protection fault. In addition, if page tables are maintained in local memory that can only be accessed from the owning processor, messages must be used, further increasing the overhead.
Second, false sharing increases as the unit of sharing gets bigger [EK89]. As an example, consider a pair of cooperating processes, executing on different processors, sharing data that resides in two different memory blocks that are in the same page. Assume that one process is updating data in one memory block while the other is simultaneously updating data in the other memory block. In a hardware coherent environment no coherence logic is invoked since the operations are in different memory blocks. But in the page-based environment, each access will likely cause a page fault since the updates are taking place to the same page. Ownership (or the right to write to the page) could switch back and forth between the two processors on every access - sometimes called the ``Ping-Pong'' effect.
One technique to reduce the ``Ping-Pong'' effect is to provide a processing window during which time access to the page won't be taken away. Any other processes faulting during this window would be delayed.
Application awareness of the memory block size (in this environment the size of a page) can be used to reduce the ping pong effect [LF92] and the coherence overhead [AH91][JD92]. Applications which manipulate rows or columns of a matrix in parallel on different processors can allocate the units of work in multiples of the page size to reduce the cost of software coherence.
For this project, we decided to modify an existing operating system to run on the prototype for the IBM Shared Memory System POWER/4. The operating system was Mach 3.0 from Carnegie-Mellon University (CMU). The Mach 3.0 system [Acc+86] was selected because of the manageable size of its multiprocessor-enabled microkernel and the pre-existence of a port to a (uniprocessor) IBM RISC System/6000.
At the heart of a Mach-based operating system is the Mach microkernel which executes on the bare hardware and exports a machine independent interface to its users. What are normally considered the typical operating system services are layered above the Mach microkernel as a set of servers that run in user mode. Since servers provide most of the traditional system services, porting an ``operating system'' that runs on Mach to a different platform is simplified because the Mach microkernel itself hides most of the machine dependencies.
Mach provides BSD functionality via a user level server -- a single Mach task with multiple threads. Since user tasks receive a coherent view of memory (Section 2), the BSD server can run unmodified on a SMC -- only the microkernel must be adapted to execute with non-coherent memory, reducing the amount of work to be done. Figure 3 shows the relationship between the microkernel and its user tasks.
Figure 3. Mach 3.0 Structure
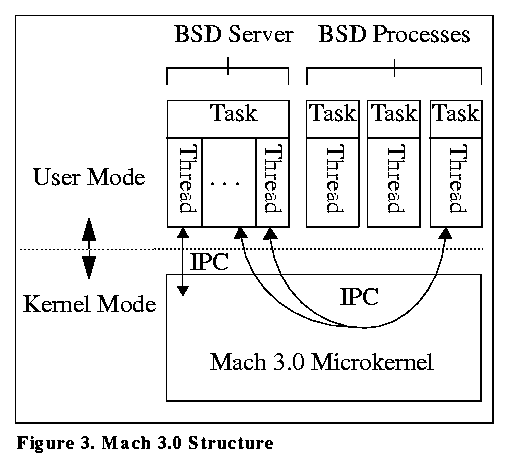
The microkernel was adapted to non-coherent memory by adhering to the Coherence Conditions listed above with one major exception. The microkernel is structured as a set of kernel threads which may execute on different processors. For the microkernel, each thread is considered a separate processor for the Coherence Conditions.
Processes that cooperate by sharing data, even on coherent machines, must do so in a way that guarantees data consistency. Mach has been designed to run on multiple processors and uses locks to maintain data integrity [Bla+91]. Mach uses different locks for different data items. This allows a high degree of parallelism since the same critical section can be executing simultaneously against different instantiations of a data structure.
The Coherence Conditions require controlling access to individual memory blocks. Since Mach uses locks for mutual exclusion, the data items protected by a specific lock cannot reside in the same memory block with data protected by a different lock. Specifically, shared data items are partitioned by their access (locking) protocol; data items protected by exactly the same protocol form a partition. Items in the same partition can be packed into the same memory block(s) and any one memory block cannot contain data from multiple partitions. Although there are optimizations to allow some of these partitions to be combined 1 this solution is reasonably efficient and is easy to compute.
Many data items are partitioned naturally by categories that more broadly describe how they are accessed. These categories also define the options available for placement in private or shared memory and the most restrictive protection that can be assigned. Table 1 summarizes these issues
Table 1. Management of Kernel Data
| Data Category | Memory Placement | Virtual Storage Mapping | Partitioning |
|---|---|---|---|
| | |||
| Read Only Constants | Private | R/O | Unpartitioned. R/O data can be distributed across all other partitions. |
| Read Only After Initialization | Shared | R/O | |
| Write one processor, Read same processor | Private | R/W owner, None for others | One per processor |
| Write one processor, Read many | Shared | R/W owner, R/O for others | |
| R/W Single Thread | Private if thread cannot migrate. Shared otherwise | R/W on active processor, None on others | One per thread |
| R/W Multiple Threads | Shared | R/W | By access protocol |
An example of the process used to partition the shared data by access protocol (the R/W Multiple Threads category) comes from the zone structure used in the kernel. The zone structure manages a pool of quickly accessible kernel memory. One zone structure is allocated for each pool. Figure 4 shows the source for the zone structure (as modified for memory block partitioning)
Figure 4. The Mach zone structure.

Access to all the members in part A is protected by locking either zone_S_lock (a Mach simple lock) or zone_C_lock (a complex lock) based on whether the memory for this zone is pageable. So the members in part A form one partition. In Mach a complex lock contains a simple lock to protect its data structures, so zone_C_lock (section B) is in a partition by itself. Finally, next_zone (section C) is a link field that joins together all of the instantiated zone structures. The queue header and the next_zone fields from all the zone structures are protected by a separate lock and form a third partition.
Each instantiation of a zone requires the allocation of three memory blocks. The MBLOCK_PAD macros have been inserted in the structure to allocate enough space to force the next element to a memory block boundary. This assumes that the structure is allocated on a block boundary. To enforce this alignment, the internal Mach memory allocation routines were changed to allocate memory on memory block boundaries regardless of the space requested.
Partitions of statically allocated external variables must also be memory block aligned and separated. To accomplish this requires an extension to the C programming language that allows alignment requirements to be specified and passed to the loader (as in GNU CC). Since this was not available in the compiler being used for the port, all external declarations of shared data were changed to definitions and moved to assembly code files where alignment facilities could be used.
The approach used in this project allows data to remain in the cache between critical section executions. Each time a critical section is entered, shared data is flushed before it is touched forcing the next reference to come from memory. Modified data is stored to memory prior to leaving the critical section thus ensuring that a valid copy exists should it be needed on another processor. This approach was used because it could be (but hasn't been) extended to have staleness ``awareness'', much like the Version Verification Scheme proposed by Tartalja and Milutinovic [TM91], which could be used to avoid the flush when cached copies aren't stale.
Some of the shared data accessed within a critical section may be static in nature. When the lock protecting the data is instantiated, the addresses and lengths of these regions are well known and don't change. The Mach functions used for initializing locks were changed to include the specification of up to two data areas which are recorded in the lock structure itself. The lock and unlock functions were changed so that these areas were flushed and stored appropriately.
Some of the data associated with locks is dynamic in nature, changing as the state of the system changes. A common example is a lock protecting a queue header (static) and all the queue chain fields of those structures linked on the queue (dynamic). There are two approaches for managing the coherence of dynamic data. The first, called the encapsulated approach, is to ensure all the data is coherent as part of the lock manipulation, much like the lock's static data described in Section 3.5.2. This requires an awareness of the structuring of the shared data, which could be provided by a routine(s) whose address is passed when the lock is initialized. Its address would be maintained in the lock's data structure, and it would be invoked as the lock is manipulated. This would be similar to a method in an object oriented language.
Another approach, called the distributed approach (the one used in this project), is to insert the cache management statements into the code that touches the shared data.
The advantage of the encapsulated approach is that it is tied to the data structures rather than the program logic. When adapting existing systems for cache coherence, intrusion into the programming logic is minimized and subsequent changes don't affect the methods that maintain coherence. The disadvantage to this approach is that all of a lock's shared data is made coherent every time the lock is used, even though in many cases, only a small portion of the data is manipulated in any one critical section.
The advantage of the distributed approach is that only those pieces of data that are actually touched while the lock is held are made coherent. A disadvantage to the distributed approach is that it is prone to over-flushing the data that is modified. The most common cause of this over-flushing is that subroutines may not be aware that some of the data that they touch may already be coherent, requiring it to also ensure its coherence.
There are situations where the operating system may wish to get a ``reasonably accurate'', advisory view of the status of a subsystem or operation, but doesn't require the precision that could only be acquired by entering a critical section. This logic does not depend on having sequentially consistent memory accesses. In these cases it would normally be acceptable to simply reference the data without incurring the overhead of the synchronization protocol. On a non-cache coherent machine, however, this is not sufficient since a stale copy of the data could be in the cache, providing instead a never-changing and ``consistently inaccurate'' view. In these cases, potentially stale data needs to be flushed from the cache prior to each access.
The goal of this project was to determine the feasibility of adapting an operating system to a non-coherent environment and to roughly measure performance. This allowed for design trade-offs that would be unacceptable in a production environment but that had little impact on our results.
Mach extends the Unix process model by separating it into a task with possibly multiple threads. The thread is the unit of scheduling. Each thread has its own state that contains such things as its instruction counter, registers, and stack. The task is the basic unit of resource allocation, and collects the common state for its threads. A task includes a paged virtual address space and protected access to system resources, including its memory mapping (all of a task's threads share the same virtual storage mapping), processors, and port capabilities. The traditional notion of a Unix process is represented by a task with a single thread.
The changes to the machine dependent code for multiprocessor execution were minimized by a design decision that restricts all threads from the same user task to execute on the same processor. In a system supporting only BSD ``processes'', this design decision only impacts the BSD single server, which is the only user task with multiple threads.
In addition, there was no policy implemented for the migration of user tasks to different processors. Mach was changed so that whenever a new task is created, a processor is selected (via round-robin) to which all threads created under the task are bound. This means that there is no load balancing built into this implementation. User threads are assigned semi-permanently to a specific processor (threads are, however, dispatched on the ``master processor'' for some portion of I/O processing). The mechanism to reassign a task and its threads to a different processor was implemented, but no policy was developed to cause the reassignment to occur.
These restrictions don't hold for kernel threads, some of which are bound to the ``master'' processor while others are free to migrate.
Thread migration is a problem in a non-cache coherent machine. The kernel's shared data that is protected by simple locks will remain coherent (threads can't yield or block while holding a lock -- so they can't be migrated while accessing this data). Kernel threads that can migrate can lose coherence to other types of data (e.g. data protected by complex locks, data on their stack).
For this reason, the kernel has been modified to keep track of the last processor on which each thread executes. Each time a thread is dispatched, this is examined, and if the thread has migrated, an Inter-Processor Communication (IPC) request is sent to the previous processor. Both the previous and the current processors invoke a routine to flush the entire contents of their data caches. This guarantees coherence.
Each processor in the POWER/4 system has non-shared access to its own I/O bus. It would have been feasible, but difficult, to merge all the processors' devices into a global device name space. Instead, only the devices from one processor, called the ``master'', are made visible. All I/O operations are funneled through the ``master''.
This implementation allowed the device drivers and interrupt handlers to execute, for the most part, without change. Stubs were added to the device drivers to bind the calling thread to the master until the I/O is queued, at which time the thread is returned to its previous state, bound again to its previous processor if appropriate.
Although an asynchronous IPC protocol would have been more efficient, a synchronous protocol was developed to handle the sixteen unique message types needed to support this project. These were implemented by adding a message to a communication queue anchored in shared memory followed by causing the other processor(s) to receive an external interrupt. The interrupts are generated by using the IPC semaphores of the Atomic Complex.
On the POWER/4 system, each processor is booted independently of the others. Any operating system designed for the RISC System/6000 architecture could boot on a single processor and function without change using only local memory. If these operating systems were booted on each of the four processors, they would operate independently, having no awareness of each other, the Atomic Complex, or the shared memory.
To accomplish the symmetric multiprocessor image on the POWER/4 architecture, the boot code was modified to coordinate activities with the other processors by use of the Atomic Complex and shared memory. As part of the kernel build process, the boot image of the Mach kernel is replicated across four disks, one disk for booting each processor. As each processor is booted, the kernel image from its disk is loaded into that processor's Local Memory. Control is passed from the hardware to the ``start'' function of the boot image, which uses the Atomic Complex to determine its CPU Number, turns on a bit representing its CPU Number in a predetermined semaphore, and decides whether it should become the master or one of the slaves.
The kernel on the master processor uses the contents of the predetermined semaphore to count and identify the processors that are active. It then initializes shared memory, copies the shared kernel data area to shared memory, and rendezvous with the slaves. All the processors then update their page tables so that the static kernel data, which will continue to be referenced at its original virtual address will be mapped to its new location at the beginning of shared memory.
The boot code interfaces with the Mach kernel, informing it that free real memory begins at the end of the kernel data (in shared memory) and continues to its end. The Mach kernel is not aware of, and does not manage, any memory other than this; all kernel and user data and all user code is allocated in shared memory. Notice that the kernel code itself remains in local memory. Each processor has its own, identical copy of the kernel code mapped to identical virtual and real addresses. This is an advantage for two reasons. First, local memory is faster than shared since it is private to the processor (no contention) and doesn't require switch latency time. Second, the kernel debugger can support processor-specific traps since its modifications take place in local memory.
When the system fails in such a way that a coherence problem is suspected, locating the problem is usually a matter of reviewing all the code that deals with the (possibly) incoherent data structure, looking for failures to flush or store. Unfortunately, it's often difficult to determine the cause. By the time the problem manifests itself in a failure, the source of incoherence may be very hard to identify.
An on-line debugger may be of little value for determining the type and source of the failure. The execution of the debugger can interfere with the cache state, hiding the fact that a stale cache line caused a problem. Several times in debugging a problem the only approach to isolating the failure was to modify the source code to report the execution time values of data and rebuild the kernel.
During the first three months of testing only three coherence problems were resolved. It became clear that it might take years of work before the modified system would run. When the fourth problem appeared, a decision was made to either develop some tools and techniques to enhance debugging, or abandon the project. Fortunately, a mechanism that could be used to detect coherence ``violations'' was developed.
The foundation for our mechanism for detecting cache violations is the ``promotion'', through macros, of the memory block size to be the same as the page size. Memory allocations occur on page boundaries and partitions that were private to a memory block are now packed into a page. Low-level operating system code was written which maintains state information for every page (partition) of shared kernel data. This code intercepts cache management operations and manipulates page table access and state information for the shared data being flushed. Accesses to this data cause program traps, which again are handled by low-level code which checks and maintains the state of the shared data, reporting inconsistencies as cache (protocol) violations.
This is essentially the same concept as is applied to provide a strongly coherent model for user applications.
The first tool developed maintains state information on a per-thread basis. Each thread's initial access to shared data pages is set to None. The macros used to invalidate and store sections of data were modified so that state information could be maintained about their use. At page fault time, the state is examined to ensure that the thread flushed the data, then its access is set to either R/O or R/W based on the type of fault. When a block is stored, the thread's access is changed to R/O.
State transitions for one thread's access to a page cause the system to examine, and possibly modify, other threads' states, reporting violations as appropriate. Consider an example where threadi invalidates some data and then blocks waiting for some event. If in the interim another thread invalidates and modifies this data, the state information for threadi is reset. If threadi is resumed and touches the data (without another invalidate), a violation will be reported. In all, there are 41 types of protocol violations that can be detected in this scheme. Those interested in seeing the page state transition diagram for this facility can refer to [Roc93].
Probably the most significant benefit of this scheme is its ability to detect most, but not all, protocol violations when running on a uniprocessor. The strength of this mechanism is that those violations it can detect are reliably reported whenever they occur.
The most significant limitation of the thread-based mechanism is that it has no awareness of locks and the data they protect. It does not always detect protocol failures that involve the improper sequencing of locking and coherence operations. This is a significant class of problems that was revealed only by implementing the Processor-Based detection as described in the next Section.
After further testing using the thread-based detection scheme revealed no more problems, the system was moved to the prototype machine. Unfortunately, the system still suffered what appeared to be data coherence problems. Recognizing that some classes of problems may not have been detected by thread-based detection, a processor-based detection scheme was developed.
In this mechanism each processor maintains information on a per-page basis. Whenever a processor's access level to a page increases (None -> R/O -> R/W) it sends a Cross Inquiry IPC message to the other processors. The receiving processors check to see if this page has been modified since it was last stored, and if so, a violation is reported (by both the sender and the receiver). This is one example of the 10 different protocol violations that can be detected using this scheme.
The effort expended to develop the testing environment was well spent. Thirty coherence problems were detected and resolved in the three weeks of testing that were required before the test cases ran cleanly. Some were of such an obscure nature that it is doubtful that they would have been found otherwise. The cause of the ``last'' problem observed before developing the testing environment was uncovered in this three week test.
This environment required, on average, 0.5 days to identify and resolve one problem. This compares to 1 month without the violation detection tool. All things being equal, the 30 problems found by the tool would have required 30 months to find without it, instead of the actual three weeks.
One characteristic of the violation detection schemes is that kernel data requires 64 times the normal amount of real memory. This required changing the kernel memory pools and increasing the real memory of the test machine to 64MB. The size of the kernel image grew from 480KB to 3.6MB.
The performance of the system with violation detection enabled is abysmal; most operations are approximately 1,000 times slower. This results from the page faulting activity. Each time a thread is dispatched, all the kernel data is mapped to None. The first reference to a page causes a program trap. If the first reference to a page is a read, then the page is mapped R/O, which causes the first write access to cause a fault as well. When an invalidate is issued, the page access is set to None, and the thread could begin faulting again. Every time a thread suspends or blocks, the pages it touched are scanned to determine whether or not they have been stored back to real memory. In addition, the access to each kernel page is set to None to prepare the state for the next thread.
It became necessary to add a facility to turn on the violation detection at will, rather than automatically at boot time. Each time the system was booted, the detection code was turned on only after it progressed to the point reached in the previous debugging session. Otherwise it took 3 days for the system to boot to the login prompt.
The most effort of this project (five person-months) was spent on the Mach microkernel (machine independent) code, categorizing the data and adding the appropriate flushing logic. The original 95,000 source lines in release MK67 required 4,000 new and modified code. Of these, 2,754 were cache flushing macros and 140 were padding macros used for aligning data in 30 different data structures. There were 82 different locks defined which represents a measure of the partitioning requirements. No count of the total number of external variable definitions was made, but 483 of them were moved to one of three assembly source files to accomplish correct virtual storage mapping and correct memory block alignment and grouping.
Approximately four person-months of effort went into changes to the machine dependent code. The original version did not support multiprocessing systems, and most of the effort was spent here. The original base of 30,821 lines of code grew to 40,023; an increase of 9,202 lines. Of these, 297 were cache flushing macros. There were 140 variable definitions which were moved to assembler files.
Developing the cache violation detection facility required approximately one month of effort. Of this, three weeks were needed to develop the thread-based model; one week for adding the processor-based code. The effort resulted in approximately 1,300 lines of C code.
The testing phase lasted approximately four months. Most of this was time spent on the POWER/4 Prototype prior to the implementation of the violation detection code (three months). After the detection code was developed, three weeks were spent testing on a uniprocessor, and one week was spent on the multiprocessor.
There is little chance that this project would have been completed without the development of the detection tools. Cache coherence bugs do not lend themselves to resolution through conventional debugging techniques.
Two benchmarks were used to measure the performance of the operating system. Each one consists of a shell script that executes, in the background, twelve instances of the same program. Since the primary objective of the project was to demonstrate correct function and not performance, a random selection from the SPEC benchmark suite was made. These benchmarks are described below in more detail.
Since runs with each combination of the four processors were desired, and since no load balancing policy was implemented in the system, there was a need to ensure that the benchmarks distributed the same number of processes to each processor. For this reason, the number of copies of the program executed simultaneously is 12, the least common multiple of 2, 3, and 4.
The Espresso benchmark executes twelve instances of espresso 2.3, an integer benchmark from U.C. Berkeley, each using the input file bca.in. Li is a CPU intensive benchmark implementing a Lisp interpreter, based on XLISP 1.6 and written in C. The benchmark was developed at Sun Microsystems. Version 1.0 of the benchmark was used.
The data structures and operations needed to run on a multiprocessor (the locks, flushing and so on) are written as macros in Mach. By changing a couple of preprocessor definitions, it is possible to ``compile out'' all the code that is necessary only because of the MP nature of Mach, producing a uniprocessor version of the system. Another interesting measurement compares this uniprocessor version of the operating system (labeled UP) with the version that has been enabled for cache coherence and multiprocessor support (labeled MP) but is still only running on one processor. The UP version can take advantage of the fact that it is running on a uniprocessor. It does not need to perform all the locking, flushing, and IPC queueing operations, since it is the only processor involved. Table 2 shows the results of executing both benchmarks on an IBM RISC System/6000 model 530 with 128MB of real memory.
Table 2. Unmodified (UP) vs. Modified (MP) On Uniprocessor
| |
RISC System/6000 Model 530 | |||
|---|---|---|---|---|
| |
Espresso (bca.in) | Li (Lisp Interpreter) | ||
| |
UP | MP | UP | MP |
| real (secs.) | 228.5 | 338.5 | 4,301.6 | 5,550.6 |
| user (secs.) | 220.3 | 243.4 | 4,229.4 | 4,698.9 |
| sys (secs.) | 4.9 | 61.3 | 67.0 | 765.7 |
| real (hh:mm:ss) | 3:49 | 5:39 | 1:11:41 | 1:32:31 |
| CPU Share | 99% | 90% | 100% | 98% |
| Speed Up | 1.00 | 0.68 | 1.00 | 0.77 |
The real fields represent the elapsed (wall clock) time for the benchmark. The user and sys fields show the accumulated amount of CPU time directly spent executing the job as divided between user mode and kernel (system) mode. The CPU Share field is calculated as real / (user + sys) and represents the portion of the CPU cycles available for the duration of the benchmark that were used directly in the execution of the jobs.
This comparison shows that the MP version provides overall throughput of between 2/3 and 3/4 that of the unmodified (UP) version. The most significant change between the two systems is the sys component. It represents the time this task was executing the kernel code which, of course, was modified for cache coherence and multiprocessor support. This is a factor of twelve larger for the MP system. Although no instrumentation was included which would help quantify the causes of the increase, there are several contributing factors.
The processor-based model implemented for user tasks does not lend itself to low overhead, concurrent accessing of shared data for cooperating processes. The cache cross interrogate (XI) protocols require less overhead when implemented in hardware rather than software (no context switching). The unit of protection is a page (rather than a cache line for hardware-based coherence schemes) which can lead to more XI traffic because of a higher incidence of false sharing.
The system, therefore, was measured for its scalability in a throughput environment using the two benchmarks described earlier. It is of value to note that even though the programs that comprise the benchmark are not themselves cooperating user processes, the BSD single server does share memory with user tasks. Each task has a three page data area that it shares with the BSD server. The server task and the emulator code in the user task share this area in R/W mode in an effort to reduce message passing through the kernel.
Table 3 shows the results of executing these benchmarks on the POWER/4 Prototype machine configured as a 1, 2, 3, and 4-way multiprocessor. Each processor had 64MB of local memory with shared access to 128MB of shared memory. The last row shows the speed up relative to the unmodified code (UP) as reported in Table 2.
Table 3. Benchmark - Multiprocessor Results
| |
POWER/4 Prototype | |||||||
|---|---|---|---|---|---|---|---|---|
| |
Espresso | Li | ||||||
| |
1 CPU | 2 CPUs | 3 CPUs | 4 CPUs | 1 CPU | 2 CPUs | 3 CPUs | 4 CPUs |
| real (secs.) | 1,005.3 | 528.5 | 382.1 | 308.5 | 18,264.3 | 9,015.5 | 6,127.3 | 4,635.6 |
| user (secs.) | 660.3 | 646.5 | 646.7 | 653.1 | 12,504.2 | 12,229.2 | 12,261.6 | 12,360.0 |
| sys (secs.) | 199.3 | 241.6 | 251.3 | 259.2 | 4,029.0 | 4,711.5 | 5,267.8 | 5,055.2 |
| real (hh:mm:ss) | 16:45 | 8:49 | 6:22 | 5:09 | 5:04:24 | 2:30:16 | 1:42:07 | 1:17:16 |
| CPU Share | 86% | 168% | 235% | 296% | 91% | 188% | 286% | 375% |
| Speed Up (MP = 1.00) | 1.00 | 1.90 | 2.63 | 3.26 | 1.00 | 2.03 | 2.98 | 3.94 |
| Speed Up (UP = 1.00) | 0.68 | 1.29 | 1.79 | 2.22 | 0.77 | 1.56 | 2.29 | 3.03 |
The most significant results from these benchmarks is that the system appears to scale well as a batch throughput machine.
As mentioned earlier, there is no load balancing policy implemented for the system; tasks are assigned permanently to a specific processor for the duration of their execution. This means that in each of the configurations, one of the processors is not only executing the same number of benchmark jobs as the others, but in addition, it is executing all of the BSD server code as well. Since the benchmark is not considered complete until all twelve jobs are finished, there is some amount of time near the end of the benchmark where all the processors, except the one that's running the BSD server, are idle. The availability of this excess capacity has not been included in the throughput analysis.
The most significant result of this project is that it proves, by example, that an existing operating system can be modified to function correctly on a non-cache coherent multiprocessor while exporting a coherent, sequentially consistent, symmetric multiprocessor view to users. Not only can it be accomplished, but it required only 14 person-months of effort to complete.
The second most significant result comes from the potential scalability of the resulting system. On a four processor SMC the system provides between 3.26 and 3.94 times the throughput of a single processor. That the system performs so well is especially promising since there was no priority given to efficiency issues during the development; the first, second, and third priorities were the functional correctness of the resulting system. Once the system was running, no effort was made to tune it or to bias the results by selective reporting. The benchmarks themselves were randomly selected.
The small scope of effort required and the promising scalability of the resulting system justify continued research. In particular, we have shown that shared memory clusters can be operated as either a cluster or as an SMP. It would also be possible to operate an SMC as a cluster of SMCs treated as SMPs.
This solution allows some subset of N processing elements of a Shared Memory Cluster to be combined into a single N-way Symmetric Multiprocessor node providing improved configuration flexibility and possibly better performance than an N-node cluster.
| Home | Comments? |