| Home | Up | Questions? |
A well-known program structure for both simulation and control systems is the event-driven program structure. An event-driven system keeps a queue of events. Each event has an associated time when it should occur. The event queue is kept sorted by time. The basic system takes each event and executes it at its desired time. The execution of an event may cause other events to be defined, each with its own associated time, These new events are then put into the event queue, and will be executed when their time comes.
In a control system, the event queue defines the activities to be done, and the system waits until the time of the next event. Thus the system spends most of its time waiting for the time of the next event, executes that event, and then waits for the next event. In a simulation system, the system can simply advance simulated time to the time of the next event; it need not spend any time waiting.
For example, consider a simple simulation of a computer processor. An event-driven simulation of the processor might have events for both the execution of instructions, for interrupts, for device activity, and so on. An instruction would start at some time, read registers, modify them appropriately, and then schedule another event, for the next instruction, at a later time, reflecting the time it takes to execute the instruction. An I/O instruction might both schedule an event for the simulation of the next instruction and also schedule an event for the start of an independent I/O operation, transferring data between an I/O device and memory. We may have multiple event streams being simulated at the same time, the events for the different streams being scheduled and executed in an interleaved manner, the time that it takes to execute one event defining the time to start execution of the next event in its stream.
For example, simulation of a multi-processor system can be a simple extension of a single-processor system. We simply allow the simultaneous creation of multiple events, one event for each processor, to simulate the instruction execution of each processor. A two processor system might have two events scheduled for time 1. One event simulates one processor taking a branch, while the other event simulates the other processor loading a value into a register. The branch might take only 1 cycle to execute, so a subsequent instruction for this processor would be scheduled to happen at time 2. The load, on the other hand, might take 4 cycles, and so the subsequent instruction for this second processor might be scheduled for time 5.
Notice that each processor will have its own data structure representing the current values of the important processor state variables. Each processor would have its own data structure containing its program counter (PC) value, its register contents, and so on. Other data structures, such as memory, might be shared, with only one copy for the entire system.
The event dispatcher can be the same, independent of the types of events that are being executed. For the simplest event system, each event consists of two basic items:
The function associated with an event defines the type of the the event. For a control system, the function modifies the system as appropriate; for a simulation system, the function modifies the simulation state to reflect the execution of the event. The function provides a place for code to change the system to reflect the execution of the event.
In general, of course, we may want to re-use the code in a function for many events. In our two-processor simulation example, we would need not only the function to be executed, but all a pointer to the data associated with the processor data to be used by that function. Thus, in general, a generic basic event system would more usefully have three items for each event:
A very important part of an event-driven system is that each event happen on time. If an event is to happen at time 5, it is important that it actually happen at time 5. In a control system, an event might measure or control some external object, and a late, or early, event might result in an incorrect measurement, or inadequate control of the object. For a simulation system, a late event might result in activity being simulated out of order, with results which do not reflect the simulated system. For example, in the two processor system, if we have two processors scheduled to execute their next instructions at time 3 and 4, but the processor for the instruction at time 3 advances the simulated clock to time 8, then the instruction schedule for time 4 would happen 4 time units late, with possibly incorrect simulated results.
Making sure that events are not delayed may mean that some events, those that take a lot of time, may need to be broken up into a chain of smaller events. Thus, for a processor instruction simulator, the basic fetch-decode-execute event might be broken down into a sequence of 3 separate events:
Breaking a larger event down into smaller events means that other activity (other events) may now take place in the time between these smaller events. This fine-grain simulation should result in more accurate simulation results.
There is a cost associated with a fine-grain simulation, however. Fine-grain event systems have many more events. Each event requires the basic system to
While each of these steps can be quite efficient, a fine-grained simulation system will simply have many more of them, with an attendant increase in computer time, even if all other factors remain the same.
In some cases, however, the increased cost of simulation may be acceptable for more accurate simulation results. Thus, a system which initially is designed and implemented with a fairly coarse-grained event structure may eventually need to be refined to a more fine-grained event structure.
Changing a coarse-grained event system to a fine-grained event system may be a very difficult task. Remember that by their nature, the basic event manipulation system should not be aware of what the events do. It simply has a function pointer, and some data, for each event. The basic event system calls the function at the appropriate time. This means that the basic program structure is as shown in Figure 1.
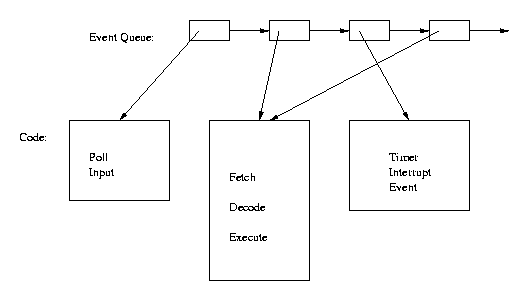
Notice that the program structure, embodied in the code segments, is essentially flat. Each code segment stands by itself and has no (hierarchical) relationship to the code for other events. The actual relationships between the code segments is embedded in the code, encoded by which events cause other events.
Making an event in an event-driven system more fine-grained involves breaking one event up into multiple events. For example, the block of code labeled "Fetch/Decode/Execute" in Figure 1 can be broken into three separate events: "Fetch", "Decode" and "Execute". The "Fetch" event executes and then schedules the "Decode" event to occur. When the "Decode" event finishes, it schedules the "Execute" event. The "Execute" event completes the loop by re-scheduling the next "Fetch" event. In a coarse-grained event scheme, time can only be simulated after the entire "Fetch/Decode/Execute" event; in the fine-grained structure, time can be associated with each of the events, allowing other events to happen between the "Fetch" and "Decode" events, for example. Figure 2 represents the code changes for this fine-grained scheme.
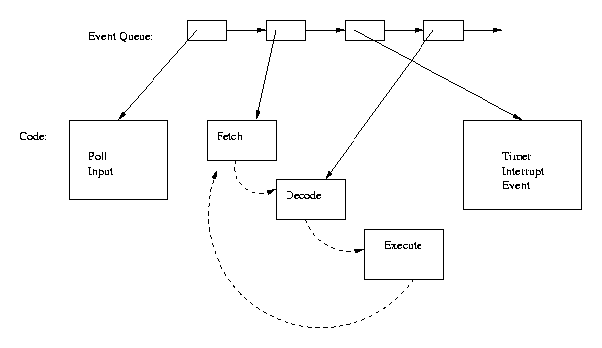
Notice that with the fine-grained event scheme, we only have one event of the three scheduled at a time. The scheduling of one event by another is the equivalent of a transfer of control from one piece of code to another, a goto. Also notice that with the fine-grained event scheme, we will execute 3 times as many events, but get no more actual code executed.
Finally, notice that when "Fetch/Decode/Execute" was one large function, information could be passed from one part to another by local variables in that function. When each is a separate event, however, there is no direct internal communication between them. Information can only be passed from "Fetch" to "Decode", for example, by (a) putting it in a global variable to which both have access, or (b) putting it in the local data structure which is associated with the event. When "Fetch" schedules "Decode" as the next event in its event stream, it will specify the three parameters to the basic event system:
Of course, although we considered the "Fetch/Decode/Execute" event above to be one piece of code, it could consist of an arbitrarily complex hierarchy of procedures and functions, not just a flat sequence of calling three other functions. This can make breaking an event into smaller events much more difficult. For example, in one real-life simulator, the "Fetch/Decode/Execute" event consisted of a code tree similar to the following pseudo-code:
Step Processor
- Fetch
- Get Instruction Address
- Translate Virtual Address to Physical Address
- Check TLBs
- Walk thru page table entries
- Read Page Table Entry
- If caches are turned on
- Read from cache
- If not in cache, fill cache
- Read cache line from Memory
- else
- Read from Memory
- Read Instruction
- If caches are turned on
- Read from cache
- If not in cache, fill cache
- Read cache line from Memory
- else
- Read from Memory
- Decode
- Search instruction table
- Compute Operand Addresses
- Execute
- switch on instruction type number to one of 339 cases.
- Typical case -- load operand
- Get Operand Address
- Translate Virtual Address to Physical Address
- Check TLBs
- Walk thru page table entries
- Read Page Table Entry
- If caches are turned on
- Read from cache
- If not in cache, fill cache
- Read cache line from Memory
- else
- Read Page Table Entry from Memory
- Compute physical address from virtual address and page table entry
- Read Operand
- If caches are turned on
- Read Operand from cache
- If not in cache, fill cache
- Read cache line from Memory
- else
- Read Operand from Memory
- update statistics
- check for interrupts to reset next instruction address
There are obvious places in this code for a common subroutine: converting a virtual address to a physical address, reading from a possible cache, and so on. We have listed everything out here to show the true size of the code for an event. Even this outline is simplistic, since it fails to consider error paths and some additional function.
Notice that there are many places in this code tree where we read from memory. In a modern computer system, memory may be a fair distance away from the processor, and so we may want to allow reading from memory to take time. Thus we want the processing which occurs after a memory read to be delayed by an arbitrary amount of time. In our event-driven system, these means each memory read should be an event. This requires that the code leading up to a memory read, and the code that follows it, must be structured as an event.
The difficulty is that we have a large amount of existing code written as a hierarchy of function and procedure calls, for a coarse-grained event system, and we wish to make it a more fine-grained event system. Unlike the event systems we have seen above, however, the code is not obviously structured to allow a basic event system to drive the code. How do we restructure the code to break it into events at arbitrary places in the existing source code tree?
The rest of this note describes a fairly mechanical process which can be applied to an existing source code tree to allow it to be event driven. This process is strictly a source code restructuring, for a language like C.
The first step is to find those points in the existing code where we wish to introduce potential delay -- that is where we need to close one event and open another. This is basically a bottom-up process. Proper use of abstraction and modularity means that a user of a higher level routine (like "Translate Virtual Address to Physical Address" in the code above) should not know how that function accomplishes its task. Hence it cannot, in general, know if a function must be broken into multiple events or not. By starting with those functions which we can identify as being broken into multiple events, then we can propagate this property up to any function which calls a function which must be broken into multiple events. In particular, calling a function which is broken into multiple events defines the point in a calling function where it is broken into two events. This defines a chain of functions to replace an existing function.
For example, the "Fetch" function in the above example, might
be written as:
Since both "translate_va_to_pa" and "read_inst_memory" involve
reading from memory, each of these define a point where "Fetch"
must be broken into a sequence of multiple events.
int Fetch(pdesc *processor)
{
int address;
int pa;
int inst;
address = processor->ia;
pa = translate_va_to_pa(address);
inst = read_inst_memory(pa);
return(inst);
}
Similarly, any function which calls "Fetch", must itself be
broken into multiple events at the call to "Fetch".
int Fetch1(pdesc *processor)
{
int address;
int pa;
int inst;
address = processor->ia;
pa = translate_va_to_pa(address);
}
Fetch2()
{
inst = read_inst_memory(pa);
}
Fetch3()
{
return(inst);
}
To maintain the proper flow of control, we must tell the
functions which end one part of "Fetch" where to continue for the
next event. This is accomplished by adding a callback
function parameter to the function call that might be
delayed. This allows "Fetch1" to indicate to
"translate_va_to_pa" that when "translate_va_to_pa" is finished,
it should resume execution with the "Fetch2" function.
Similarly, any function calling "Fetch" must indicate
to "Fetch" what function should be called when "Fetch" is
finished, by passing a callback function to "Fetch":
In this case, "Fetch1" asks to be continued at "Fetch2",
"Fetch2" asks to be continued at "Fetch3",
and "Fetch3", being the final part of "Fetch",
continues at the callback function for "Fetch".
int Fetch1(pdesc *processor, cbf callback)
{
int address;
int pa;
int inst;
address = processor->ia;
pa = translate_va_to_pa(address, Fetch2);
}
Fetch2()
{
inst = read_inst_memory(pa, Fetch3);
}
Fetch3()
{
callback();
}
Notice that "Fetch2" needs information from "Fetch1", and "Fetch3" needs information from "Fetch2" and must itself return information to its caller. The event system allows each event to specify both the function to be called and the data to be passed to it. We will need to define a data structure to hold the information that must be passed from "Fetch1" to "Fetch2". In C this will be a struct. The struct will hold the parameters and local variables of the function.
First, we must redefine all functions to not return a function value. In the above example, "translate_va_to_pa" took an address, performed some computation on it (which involved reading memory, and hence might be delayed and scheduled as a separate later event), and returned a new address as its value. This is standard programming practice. However in an event system, the value will be computed by one event and must be used by another event. There is no mechanism to pass an arbitrary (typed) value from one event to another.
To work around this, we redefine any function which returns a
value to return that value using call-by-reference through an
additional pointer parameter of the correct type. For example,
"translate_va_to_pa" would take two parameters: the value to
translate and the address in the program of the location to hold
the translated value. Each function also gains a callback function
parameter, and the data that is to be passed to the callback function.
Thus, a function such as:
is converted to:
t0 name(t1 p1, t2 p2, ..., tn pn)
{
...
return(v0);
}
The function type has been replaced by an additional call-by-reference
parameter, as well as the callback function and its data. The "return"
statement is replaced by
name(t1 p1, t2 p2, ..., tn pn, t0 *p0, cbf callback, void *data)
{
...
*p0 = v0;
NewEvent(time, callback, data);
return;
}
Any function calling one of these modified functions must
change its call accordingly. For example, in our running
example, we will need to change the way that we call
"translate_va_to_pa" and "read_inst_memory":
void Fetch1(pdesc *processor, int *p0, cbf callback)
{
int address;
int pa;
int inst;
address = processor->ia;
translate_va_to_pa(address, &pa, Fetch2);
}
Fetch2()
{
read_inst_memory(pa, &inst, Fetch3);
}
Fetch3()
{
*p0 = inst;
callback();
return;
}
Once we have redefined our functions to add any returned values
as well as the callback function and its data, we can then define
the data structure that is used for this family of events. The data
structure keeps all parameters (including the new ones that we
just introduced) and all local variables. This structure is
passed from one part of the function to another, so that they
can have access to all the data they need for their work.
Several changes are needed at this point:
struct fetch_data
{
pdesc *processor;
int *p0;
cbf callback;
void *data;
int address;
int pa;
int inst;
};
void Fetch1(pdesc *processor, int *p0, cbf callback, void *data)
{
fetch_data *sp;
sp->processor = processor;
sp->p0 = p0;
sp->callback = callback;
sp->data = data;
sp->address = processor->ia;
translate_va_to_pa(sp->address, &sp->pa, Fetch2, sp);
}
void Fetch2(void *data)
{
fetch_data *sp = (fetch_data *)data;
read_inst_memory(sp->pa, &sp->inst, Fetch3, sp);
}
void Fetch3(void *data)
{
fetch_data *sp = (fetch_data *)data;
*(sp->p0) = sp->inst;
sp->callback(sp->data);
return;
}
There are various optimizations that are possible. For example, although all local variables can be put in the data structure for a set of related functions, it may not be necessary. Local variables which are defined and used only in one of the functions can clearly be left out of the data structure and instead declared as a local variable for that one function. Similarly, if parameters are used only in the first function, they need not be put into the data structure. The data structure is used to pass values from one function to another, so we only need those parameters or variables whose value is defined in one, and used in another.
Functions may be produced which are degenerate, in that they
perform no useful computation, but simply transfer control to
another function or callback. For example,
Such a function could be optimized away by replacing all
references to it with a reference to
void F7(void *data)
{
func_data *sp = (func_data *)data;
sp->callback(sp->data);
return;
}
sp->callback,
eliminating the middleman.
A final question is where the space should be allocated for the data structure. If the function can only be in use once, a simple global declaration can be used to allocate space for the data structure.
More likely the function can be used more than once (at the same time), but each use is associated with some object. For example, in the "Fetch" example, an instruction is probably associated with a processor -- each processor would only execute one instruction at a time, although multiple processors may mean several instructions are in process at the same time. In this case, the data structure can be a part of the data structure associated with the object.
A final possibility is to "malloc" the space when the first function is entered, and free it when we leave the last function.
Stepping back and looking at this transformation, we can see that the data structure associated with each set of functions is, effectively, a stack frame, and the callback function is, effectively, a return address. Thus, what we have done is implement, at the source code level, the basic stack mechanism used by procedural languages, like C, to implement hierarchical function calls. This allows us to use these directly at the top level as necessary for an event-driven system.
The basic problem is to take an existing coarse-grained event system and allow it to be more fine-grained by breaking events into sequences of events at appropriate points. This means that, in general, we will start an event, burrow down the function calling sequence until at some point we need to stop this event and schedule a new one to resume later from where we currently are. To resume from our current location, we will need to re-establish the current execution context, which is to say, its stack of local variables and return addresses. Our code transformation makes this context explicit.
An alternative would be a system that could save and restore the event's current stack -- essentially a threading package. This takes the event structuring out of the hands of the application itself and makes it dependent upon another software package. In addition a threading package must be aware of the specific processor and operating system architecture that is used by the event system, since it must know how the system represents the stack, how to switch stacks, and so on. This makes the system platform dependent; a porting will be necessary to move it to an new system.
The process described here is strictly a source code transformation and is completely portable.
| Home | Comments? |