Figure 1. Graph representation of machine language instructions.
| Home | Up | Questions? |
We present three techniques to reduce the amount of memory that programs need in order to execute. The first two techniques attempt to reduce the size of the program text (one succeeds and the other apparently does not). The last technique reorders the program text to reduce the size of its working set.
Many programs require a large amount of memory. This is the result of (a) the availability of large amounts of physical memory, (b) the lower cost of memory, (c) the wide use of virtual memory techniques to create 32-bit virtual address spaces, (d) the nature of RISC instruction sets, and (e) the increased complexity of application programs to be user-friendly as well as provide increased functionality, among other factors.
On the IBM RISC System 6000, for example, the X window server object file is 1,590,950 bytes; mwm is 268,474 bytes, emacs is 2,193,384, perl is 660,928 and so on. These numbers give us a feel for the size of these programs. Other commonly used programs (vi, Interleaf, Frame, info, and so on) are often quite large.
If these commonly used programs could be made smaller, they could run on a larger selection of machines, using fewer memory resources.
There are many ways to make programs use less memory. The most successful will involve redesigning the program to take memory space into consideration, resulting in different algorithms and different coding techniques.
However, another set of techniques can be applied to the finished binary program without requiring redesign and recoding. These techniques must not change the semantics of the program, but rather look for possible ways to decrease the size of the program while having it execute the exact same sequence of instructions. In the following we are looking only at ways to reduce the total number of instructions in the program. We assume the program has been completely compiled and linked and is ready to execute.
As an object of study, let us use the IBM Microkernel for the PowerPC. Compiled by the Metaware High C compiler, the compiled and linked object file is initially 128,457 instructions.
The simplest solution to decreasing the amount of space that a program needs to run is to make sure that we do not have more instructions than are necessary. We want to reduce code size by eliminating common code. If you look at the code which makes up a program, you can occasionally find blocks of identical code. For example, if we look at an a disassembled version of the IBM Microkernel for the PowerPC, we can find three separate basic blocks of the form:
0xf0160168: lwz r0,0x74(r1) # 0x80010074 0xf016016c: lwz r14,0x28(r1) # 0x81c10028 0xf0160170: lwz r15,0x2c(r1) # 0x81e1002c 0xf0160174: lwz r16,0x30(r1) # 0x82010030 0xf0160178: lwz r17,0x34(r1) # 0x82210034 0xf016017c: lwz r18,0x38(r1) # 0x82410038 0xf0160180: lwz r19,0x3c(r1) # 0x8261003c 0xf0160184: lwz r20,0x40(r1) # 0x82810040 0xf0160188: lwz r21,0x44(r1) # 0x82a10044 0xf016018c: lwz r22,0x48(r1) # 0x82c10048 0xf0160190: lwz r23,0x4c(r1) # 0x82e1004c 0xf0160194: lwz r24,0x50(r1) # 0x83010050 0xf0160198: lwz r25,0x54(r1) # 0x83210054 0xf016019c: lwz r26,0x58(r1) # 0x83410058 0xf01601a0: lwz r27,0x5c(r1) # 0x8361005c 0xf01601a4: lwz r28,0x60(r1) # 0x83810060 0xf01601a8: lwz r29,0x64(r1) # 0x83a10064 0xf01601ac: lwz r30,0x68(r1) # 0x83c10068 0xf01601b0: lwz r31,0x6c(r1) # 0x83e1006c 0xf01601b4: mtspr r0,LR # 0x7c0803a6 0xf01601b8: addi r1,r1,0x70 # 0x38210070 0xf01601bc: blr # 0x4e800020One copy of this code starts at location 0xf0160168, another copy starts at location 0xf0161c44, and a third starts at location 0xf0166b40. We can eliminate the duplicate code segments by replacing the duplicate segments with an unconditional branch to the segment at location 0xf0160168. If we could eliminate the second and third copies of this code, we could reduce the size of the executable program by 168 bytes. If a program has enough duplicate code, it may be possible to substantially reduce the size of a program by eliminating the duplicate code.
How do we find duplicate instructions? For example, there are 1111 instances of the instruction "cmpi cr0,r12,0x0" in the IBM Microkernel, but we can't just delete the 1110 duplicates. The resulting program would not work the same.
Our approach is to look for identical instructions which after they are executed continue to execute at the same place. For example, notice that in the large block of code above, each of the three copies will all continue execution at the instruction whose address is in the link register. Another example would be the sequence of instructions:
0xf0100390: stw r0,0x0(r3)
b 0xf01004f0
...
0xf0100428: stw r0,0x0(r3)
b 0xf01004f0
...
0xf0100460: stw r0,0x0(r3)
b 0xf01004f0
...
0xf0100498: stw r0,0x0(r3)
b 0xf01004f0
...
In this case, once execution starts at any of the addresses 0xf0100390,
0xf0100428, 0xf0100460, or 0xf0100498, the behaviour of the program is
identical: execute "stw r0,0x0(r3)" and then branch to 0xf01004f0. We
can shorten the program by replacing this code with:
0xf0100390: stw r0,0x0(r3)
b 0xf01004f0
...
0xf0100428: b 0xf0100390
...
0xf0100460: b 0xf0100390
...
0xf0100498: b 0xf0100390
...
In addition, if we were to have a branch to any of 0xf0100428, 0xf0100460, or 0xf0100498, it could be replaced with a direct branch to 0xf0100390.
And, if the instruction before 0xf01004f0 is a branch, so that it does not fall through to 0xf01004f0, then we could move the code from 0xf01004f0 to just after 0xf0100390, eliminating the branch.
Thus we can reduce the size of programs by looking for unnecessary branches and for blocks with identical sequences of instructions which also branch to the same location.
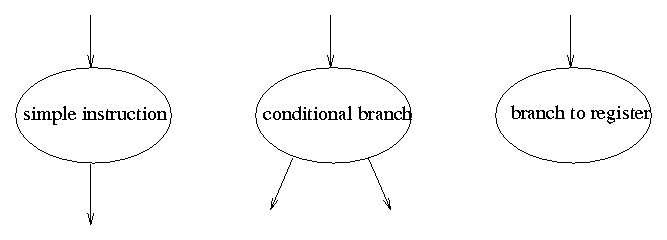
To determine how much savings these rules will generate, we can consider each instruction in the program as a node in a graph and construct a graph showing control flow. Most instructions have one input and one output: control flows from the instruction before and goes to the instruction after. Unconditional branch instructions can be folded into the previous instruction and change where the output of the previous instruction goes. Some instructions, such as conditional branches, have two possible outputs: the next instruction in memory or the instruction whose address is given by the conditional branch. Another set of instructions are computed branches: branches whose target is an address in a register have no outputs in the graph. See Figure 1.
Figure 1. Graph representation of machine language instructions.
In this graph representation of a program, instructions can be combined with other identical instructions (same opcode and operands) with the same destination. Once a pair of instructions is collapsed, other nodes may have the same destination and can also be collapsed, allowing entire chains, such as the blocks shown above to be merged.
Applying this technique to the IBM Microkernel, compiled by the Metaware High C compiler, we found 15,954 out of 128,457 instructions that could be collapsed, a savings of 12.4%. Compiling the IBM Microkernel with the IBM Visual Age C compiler, we can reduce the Microkernel from 127,375 instructions to 110,430 instructions, removing 16,945 instructions, a savings of 13.3 percent.
The traditional way to create a large application in C is to write several separate files, each containing a small related part of the application, and compile them separately. The separate object files are then combined by a link step to create the final executable. For example, to compile the "xprog" application from its source files, we might execute:
cc -O scope.c -c cc -O common.c -c cc -O fd.c -c cc -O server.c -c cc -O decode11.c -c cc -O print11.c -c cc -O prtype.c -c cc -O itype.c -c cc scope.o common.o fd.o server.o decode11.o print11.o prtype.o itype.o -o xprogNotice, however, that this means that the compiler must generate code for the source in, for example, fd.c, without any knowledge of how that code will be used or about the specifics of other code that it calls. That is, the compilation is local to each file, and cannot use global information about the entire application. A limited amount of global information may be available from function prototypes.
We suggest that it is possible to easily create a new main program which provides the entire application to the compiler at one time. This allows the compiler to use global information about the entire program to both (a) generate more efficient code, and (b) do a better job of error checking.
To get the entire application compiled at one time, we could merge the source files into one very large source file, but this is unwieldy from a maintenance point of view. However, we can use the C language "#include" statement to do a very similar thing.
We generate a new main program, consisting only of #include statements. For each source file, we #include that source file in the new main program. We can add #define and #undef statements for any preprocessor variables on the command line if necessary.
For example, for the above program, we define a new file "all.c" consisting of:
#include "scope.c" #include "common.c" #include "fd.c" #include "server.c" #include "decode11.c" #include "print11.c" #include "prtype.c" #include "itype.c"This new "all.c" program can be compiled by a simple "cc -O all.c -o xprog" to produce an equivalent program to the original multi-file application, but with the added advantage that the compiler can "see" the entire application at once, and hence should be able to generate better code.
For example, for the given program, we have a savings with the XLC compiler on the IBM RISC System 6000 of 3364 bytes of code, reducing the size of the object program from 86304 bytes to 82940 bytes, about 4% savings in space. Most of this savings is from saving the CROR 15,15,15 instruction which is normally inserted following a branch and link (bl) for the 6000, but there are additional savings from global register optimization, instruction scheduling, and even from eliminating entire routines.
In scope.c, for example, we have the routine SetUpStdin() which consists of
SetUpStdin()
{
enterprocedure("SetUpStdin");
}
Compiled separately this becomes:
mfspr r0,LR
stu SP,-64(SP)
st r0,72(SP)
l r0,T.112._scope__(RTOC)
ai r3,r0,640
bl .enterprocedure
cror CR7_SO,CR7_SO,CR7_SO
l r12,72(SP)
ai SP,SP,64
mtspr LR,r12
br
But when included as part of the same compilation as enterprocedure,
it is compiled into
l r0,T.928._all__(RTOC)
ai r3,r0,640
b .enterprocedure
There are some possible problems with this compilation approach:
(1) The time it takes to compile increases because of the use of global information. To compile all of the separate files and link them together took 3 minutes, 10 seconds. As one file, it took 8 minutes, 43 seconds, an increase from 190 to 523 seconds, or 275% longer. But, of course, the objective is simply to produce the most optimal code once the program works and is debugged, so the longer compile time should not be a problem for program development, only for the final build for distribution.
(2) Compilers sometimes cannot handle the very large programs that may be generated in this way. It is possible to generate what the compiler sees as a very large program, sometimes exceeding limits within the compiler of various tables.
(3) Programs must be written to allow this form of compilation. Header files, for example, which may be included by many of the source files must be protected from being included several times. This is easily done, and is often a part of standard coding practices.
In addition, the names and use of static variables and procedures must be carefully controlled, since when all source files are combined into one, the scoping rules for static names changes.
The main problems that we ran into in making a program compile in this fashion were (1) missing function prototypes and (2) multiple definitions of the same preprocessor variable. In the first case, the first use of a function with no prototype would default to assuming it was a function returning "int". When the function was eventually defined, the assumption was sometimes incorrect, resulting in a compilation error. In the second case, C allows multiple identical definitions of the same preprocessor variable or macro, but we often found multiple different definitions, either different variables with the same name or the same macro with syntactically different definitions (such as max(a,b) and max(x,y)).
It is fairly easy to construct or modify programs to be compiled this way, however, and if compilers are written to perform global optimization, substantial code improvement may result.
For the IBM Microkernel, we can create one file which "includes" the 215 C files for the operating system kernel. While the original file is only 215 lines of code, it expands to 193,530 lines (7,157,622 characters) after being run through the C preprocessor. (Only 84,084 lines of 3,477,609 characters when the preprocessor file and line control information is deleted).
Mega-compiling the entire IBM Microkernel with the Metaware High C compiler produces an object file of 129,481 instructions instead of the 128,457 instructions for traditional multiple file compilation, an increase of 1,024 instructions.
Using the IBM Visual Age C compiler is a different story. Mega-compiling takes substantially more time (over 18 hours) but produces an object file of 145,807 compared with 127,375 instructions for more traditional multiple file compilation.
Examining the generated assembly instructions, it appears that the both compilers are overwhelmed by the size of the input and are unable to generate the same quality of code -- the differences are the result of additional register to register movement of data that is handled by simple register renaming in the traditional compilation, and failing to recognize other similar simple code optimizations. Thus, although more information is available to the compiler, both of these compilers appear to be overwhelmed by the size of the input program.
However, if we then compress the mega-compiled versions, using the technique discussed above to discard duplicate instructions, the Metaware output drops from 129,481 to 113,526 instructions (a savings of 12.3 percent), and the Visual Age output drops from 145,807 to 128,571 instructions (a savings of 11.8 percent).
Table 1 shows the sizes of the various combinations of normal and meta-compiling followed by compressing the resulting objects.
| MetaWare | Normal | Compressed |
| Normal Compiling | 128,457 | 112,503 |
| Mega-Compiling | 129,481 | 113,526 |
| Visual Age | Normal | Compressed |
| Normal Compiling | 127,375 | 110,430 |
| Mega-Compiling | 145,807 | 128,571 |
If all of the code that is contained in large programs were used much of the time, there would be little to do to save space. However, it seems unlikely to us that all of the code is used most of the time. Rather, we suspect that these programs contain a large amount of code that is seldom, if ever, used. We suspect that the central core of the programs is fairly small, with a larger amount of infrequently used code. A rule of thumb in computer science, for example, suggests that 80 percent of the execution time of a program is spent in 20 percent of the program. Sometimes the more extreme 90/10 ratio is used.
The practical impact of this depends upon how the program is organized. In a demand-paged virtual memory system, code is not brought into memory until it is used. Thus, a program can have a very large binary object file but still take little physical memory at run time. We do not see this happening with real programs, however. One reason for this is that the unit of allocation and transfer in a demand-paged virtual memory system is the page, not the individual instruction. When any instruction on a page is used, the entire page is brought into memory. Thus, if only a few instructions on that page are used, the rest of the page is effectively wasted. If we could bring in only those instructions that are needed, and not all the others which happen to sit on the same page, we could reduce the amount of memory needed by an application to just that memory that is actually used.
We need not deal at the level of individual instructions however. Once an instruction is executed, control normally passes to the next instruction after it in memory. This sequential flow of execution is interrupted only by branches. A branch (or jump) defines the address of the next instruction to be executed. A branch can be either conditional or unconditional. A basic block is a sequence of instructions starting with a (possible) target of a branch and ending with a branch. Since execution always continues until it is redirected by a branch, we know that whenever the first instruction of a basic block is executed, every instruction after it is executed until the end of the basic block.
For example, consider a simple if-statement:
if (condition) then-part else-partIn machine language, this would consist of three basic blocks:
bb1: compute condition
branch-if-false to bb3
bb2: then-part
branch to bb4
bb3: else-part
bb4:
An actual if-statement with a compound condition and complex
statements for the then-part and else-part might actually consist of
many basic blocks. In addition either the basic block bb2 or basic
block bb3 may be quite large. The difficulty in memory usage is when
the condition of the if-statement is such that only one part of the
condition is (almost) always executed. For example, the condition may
test for a possible, but unlikely, error condition. In this case the
basic block will take up space in the allocated page, even though the
code in the basic block is never used. For example, if basic block
bb2 is the treatment of an error condition which almost never happens,
the code for bb2 is none-the-less brought into memory when bb1 and bb3
are executed.
Thus, a demand paged virtual memory system would be more memory efficient if it worked with units of basic blocks. If a basic block is referenced (by a branch to its first instruction), we know that each and every other instruction in the basic block will also be used. The end of the basic block will be a branch to the next basic block. In the execution of a program, some basic blocks will be executed frequently, others less frequently, many never at all. If virtual memory was based on basic blocks, those which were never executed would never be brought into memory.
Basic blocks tend to be fairly small. The X11 window server for the IBM 6000, has 212,985 instructions divided into 36,190 basic blocks (an average of 5.88 instructions per basic block). The basic blocks range from 2 to 160 instructions.
Demand paged virtual memory systems do not work with small variable sized basic blocks, however, since keeping track of and allocating memory for small variable sized program units would require substantial overhead. More commonly, virtual memory systems use fixed sized pages of, for example, 4096 bytes. As a result, each page contains many different basic blocks. When one basic block in the page is executed, all basic blocks in that page are brought into memory, even though some (perhaps many) of these basic blocks may not be used.
Notice, however, that with a very small change in the code that is generated for a program, basic blocks need not be put in memory in the order that they are written in a program. For the if-statement example from above, we could generate code as:
bb1: compute condition
branch-if-false to bb3
branch to bb2
bb2: then-part
branch to bb4
bb3: else-part
branch to bb4
bb4:
We have added two unconditional branches to the original code. With
this code, we can freely move either block bb2 or block bb3 anywhere
in memory. Control is always entered at the beginning of the block
with a branch (never by just "falling through"), and always leaves by
an explicit branch.
The addition of explicit branches allows basic blocks to be freely put in memory wherever is convenient, not necessarily only in the order that they are written in the original program. For example, we can rearrange the above code to move basic block bb2 to a remote part of memory.
bb1: compute condition
branch-if-false to bb3
branch to bb2
bb3: else-part bb2: then-part
branch to bb4 branch to bb4
bb4:
(We could then optimize the code by reversing the sense of the
conditional branch to branch-if-true to bb2 rather than the current
branch-if-false to bb3.)
With this freedom, we can now re-order the basic blocks of important programs, like x11, mwm, vi, emacs, and so on, so that the frequently used basic blocks are in the same pages, and infrequently used basic blocks are in pages with other infrequently used basic blocks which would normally never be used.
This approach suggests that it is possible to reduce the working set of a program, the amount of physical memory it needs as it executes, without rewriting the program, but simply by re-ordering its basic blocks in the pages that it uses. Although the complete X11 server may be 2 Mbytes, only a (much) smaller part of it would typically be in memory.
To test this approach to reducing the working set of a demand paged program, we have developed an ability to identify, instrument and re-order the basic blocks of large programs. Testing it on the X11 window server, we have been able to reduce its memory requirements from 226 pages to 101 pages (a 55% memory saving).
This work is very similar in motivation to work done during the early days of virtual memory. See references [Hatfield and Gerald 1971], [Masuda, et. al. 1974], and [Ferrari 1976].
The same ideas and mechanisms can be used to improve cache line usage. In fact the size of a basic block more closely fits typical cache block sizes.
| Home | Comments? |