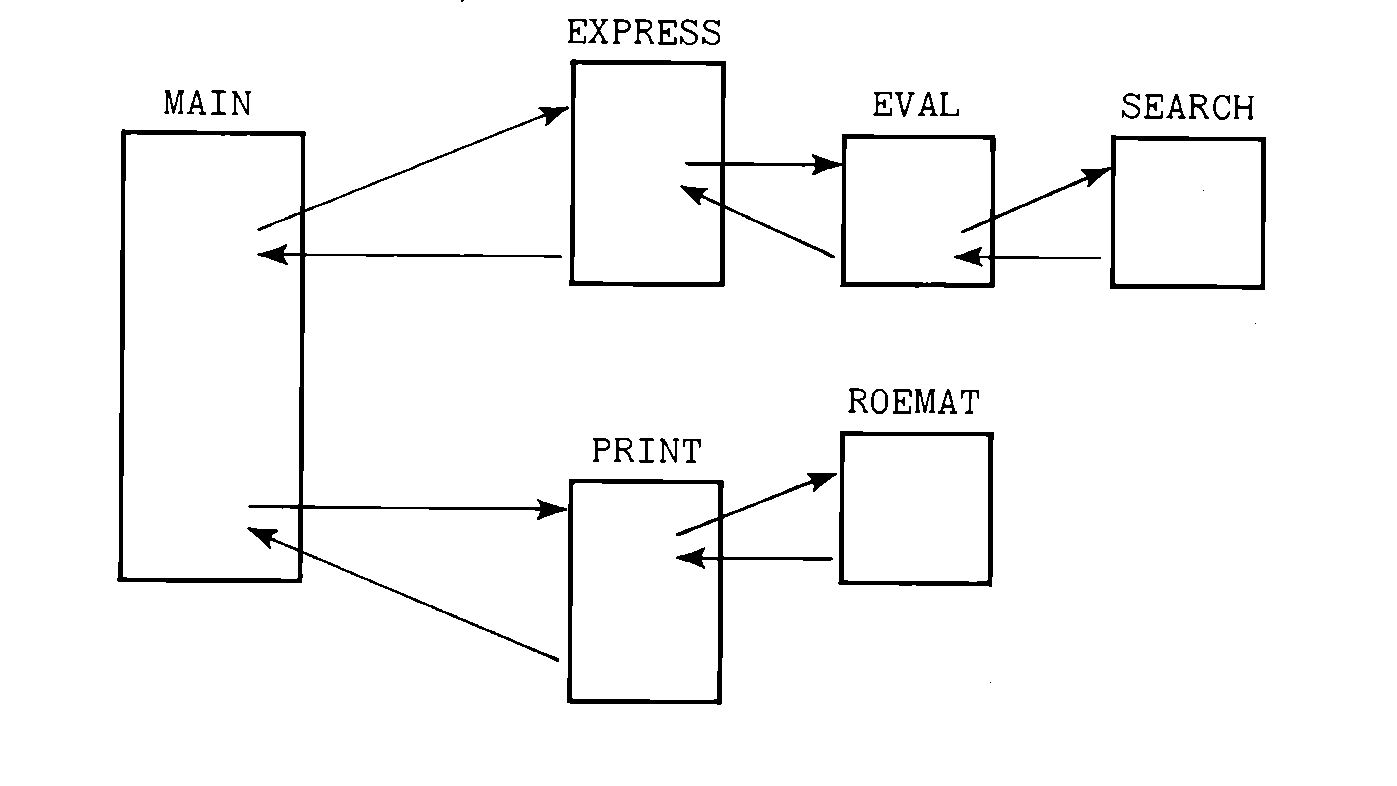
 FIGURE 6.1 A main program and its set
of subroutines (the main program calls two subroutines; each of these may
then call other subroutines).
FIGURE 6.1 A main program and its set
of subroutines (the main program calls two subroutines; each of these may
then call other subroutines).
After a programmer has written a few assembly language programs, a number of things become obvious. One is the repetitive nature of assembly language programming. For almost every program, code must be written for inputting data and converting from character code, and code must be written for formatting and outputting results. This code is often very similar from program to program. It may be necessary to input or output at several points in the algorithm being programmed, so within the same program similar code must be written in several places.
This problem is compounded by the very low level of instructions available in assembly language. The operations performed by an assembly language statement are very simple, and to program even the simplest computations may take tens or hundreds of these simple instructions. To have to write the code necessary to effect some logically simple higher-level operation (such as summing the elements of an array, or counting the number of blanks in a line, or searching an array for the maximum element, and so on) more than once becomes tedious and boring.
For these reasons, subroutines are a standard programming technique of assembly language programmers (among others). A subroutine is a sequence of instructions which is a logical unit. Subroutines are also called procedures or functions. Their original and main purpose is to reduce the amount of code which must be repetitively written for a program. This makes assembly language programming easier and faster. Subroutines also allow code by another programmer to be used in a different program than it was originally written for.
Another effect of subroutines is to free the assembly language programmer from thinking only in terms of the instructions and data types provided by the hardware computer. Subroutines can provide the programmer with the opportunity to think and design a program in terms of abstract data types and instructions for these data types. For instance, MIX provides only the basic data types of integer numbers, floating point numbers, and characters (bytes). It does not provide arrays, or instructions to manipulate arrays. However, if we write a set of subroutines which add, subtract, compare, copy, input, and output arrays, then we can program in an extended instruction set, an instruction set which does have instructions to manipulate arrays. When it is necessary to actually operate on an array, the instruction is written as a call to the appropriate subroutine. Thus, subroutines free the programmer from some of the constraints of assembly language programming.
In this chapter, we consider many of the ideas, techniques and conventions which have developed regarding subroutines and their use. We are interested simply in the mechanics of how to write a subroutine and how to use it. Much of this information is applicable to both assembly language programming and higher-level language programming.
FIGURE 6.1 A main program and its set
of subroutines (the main program calls two subroutines; each of these may
then call other subroutines).
A subroutine is a closed piece of a program which has some logical function. It is executed by transferring control to its entry point. The subroutine executes, performing the task for which it was written and then returns to the program which called it. A subroutine may be completely self-contained and have the code to do everything itself, or it may call another subroutine.
A program is made up of a main program and subroutines. These subroutines are the subroutines which the main program calls, the subroutines which are called by the subroutines which are called by the main program, the subroutines which are called by the subroutines which are called by the subroutines which are called by the main program, and so on. Both the main program and the subroutines can be called routines. For each call, two routines are involved: the calling routine and the called routine.
A subroutine normally has a name. The name of the subroutine is often also the name of its entry point, the address where execution of the subroutine should begin. A subroutine is called by transferring control to the entry point of the subroutine. When the subroutine completes its execution, it will return control back to the calling routine. Normally, control is returned to the instruction immediately following the call in the calling routine. The address of this instruction is called the return address. Notice that if the subroutine is called from two different locations in the calling routine (or from two different calling routines) it will need to return control to two different addresses after it is through with its execution. This requires that every call of a subroutine not only transfer control to the entry point of the subroutine but also supply it with a return address where it should transfer control upon completion of its code.
On the MIX machine, subroutine calls are made by using the jump instructions to transfer control to a subroutine. The J register has been specifically designed to be used for supplying the return address to the called routine. When a JMP is executed to the entry point of a subroutine, the address of the instruction following the JMP is put into the J register. Thus the J register has the return address for the subroutine call.
The called routine must save the J register, and when the subroutine finishes its task, return to that address. This is done by
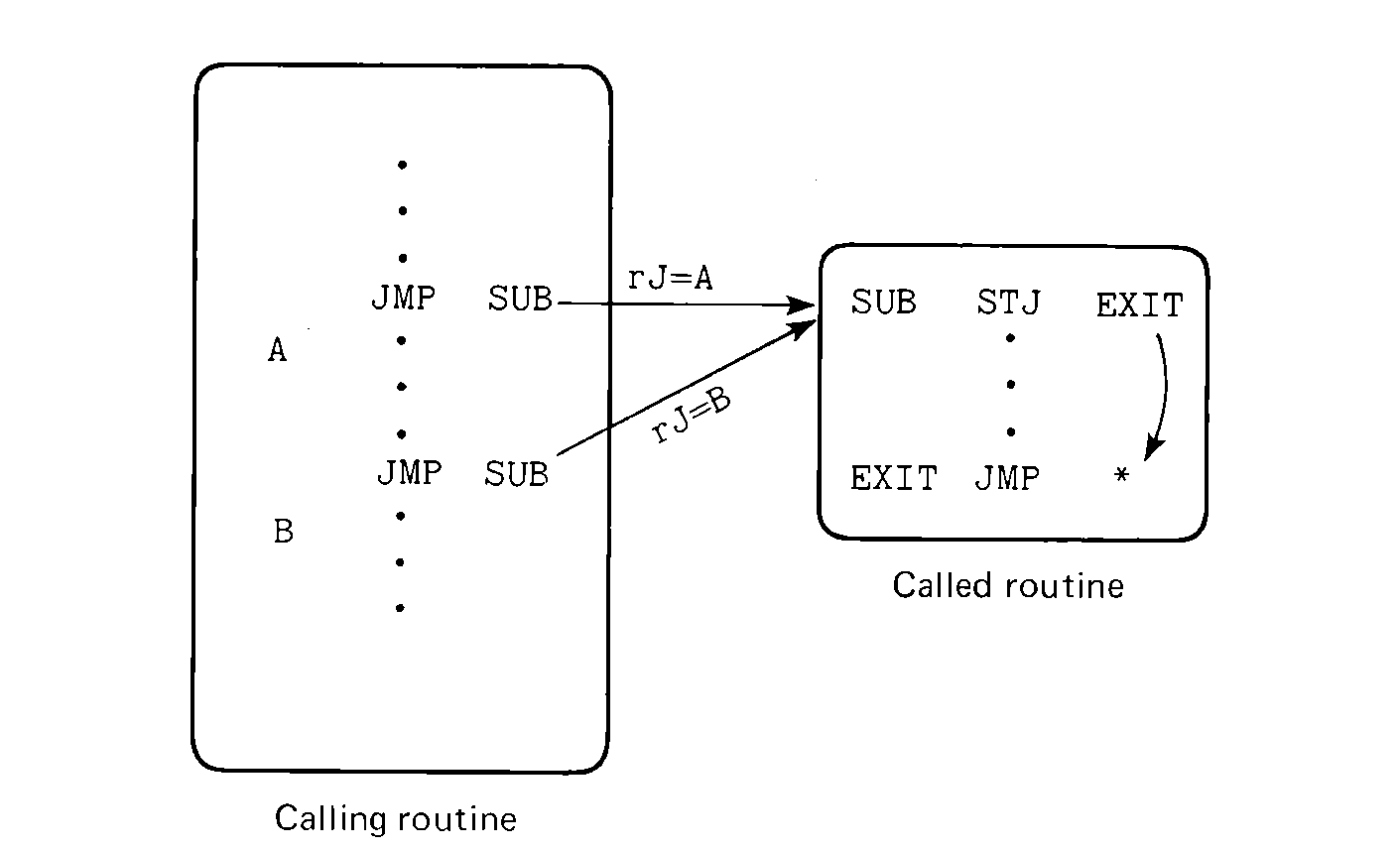 FIGURE 6.2 Illustration of the
relationship between a calling routine and a called routine, and how the
return address is passed.
FIGURE 6.2 Illustration of the
relationship between a calling routine and a called routine, and how the
return address is passed.
As a simple example of a subroutine, consider a subroutine which computes the sum of the elements of an array INCOME of length 10. The subroutine could be
The subroutine given above (SUMMER) used the A register and index register 1 in the computation of the sum. It is possible that the calling routine was also using these registers to store important values for its own computations. When the subroutine is called, it is necessary to save these registers and restore them before the calling routine is resumed. If we let P be the set of registers used by the calling routine which need to be saved and Q be the set of registers used by the called routine, then the intersection of P and Q, those registers used by both the calling and called routines, are the only registers which need to be saved. Any register which is not used by the calling program, or is not used by the called program, or is not used by either, need not be saved.
There are two places that the saving and restoring of registers can be done. The registers can be saved in the calling program before the subroutine is called and restored after the subroutine returns. Alternatively, they can be saved in the subroutine before it modifies anything, and restored right before the subroutine returns to the calling routine. Notice that only the intersection of the set of registers used by calling and called routines need be saved. However neither routine may know what the other routine uses. Often different routines are programmed by different programmers, or at different times. It is considered poor programming practice to make assumptions about how a subroutine works internally. Thus, since neither routine knows the registers used by the Other, they are forced to save all the registers they use. If the calling routine saves and restores registers, then it should save all of the registers that it uses. If the called routine saves and restores registers, then it should save all of the registers it may need to use.
The question as to which routine, called or calling, saves registers can be decided either way. If the calling routine generally needs only a few registers saved, then it may save them. On the other hand, if the called routine only uses a few registers, it may save them itself. Different routines may save registers or assume that they are saved by someone else as long as the decisions are consistent. It is even acceptable (although wasteful) for both the calling and called routine to save the registers. What must be avoided is a situation where the calling routine assumes that the called routine will save registers, and vice versa, resulting in neither routine saving them.
To prevent any possible problem of forgetting to save and restore a register, many programmers adopt a personal rule to always save all registers used in a called routine, in that called routine. This convention means that the calling program need not worry about the value of the registers when it calls a subroutine, and eliminates a major source of errors in assembly language programming.
Using this rule, we would rewrite our subroutine SUMMER given above as follows
In the above code, we stored the value of index register 1 in the temporary variable SUMTEMP1. This extra temporary variable could have been eliminated by saving and restoring the index register as follows.
The extra code which has been added to the beginning of the subroutine which is only necessary because the code is a subroutine is called the prologue of the subroutine; the code at the end is the epilogue. The prologue typically consists of instructions to store the return address and save registers. The epilogue consists of code to restore the registers and transfer control back to the calling program.
If the registers are to be saved and/or if the computation is long enough or complicated enough, the subroutine may very well need to store values in memory for its own private use. At the same time, it may be necessary for the subroutine to access some variables in the main program. Variables which are meant solely for the internal coding of the subroutine and are never used by any other routine are local to that routine. Variables which may be accessed by many routines are called global variables. Global variables are external to the routines which access them.
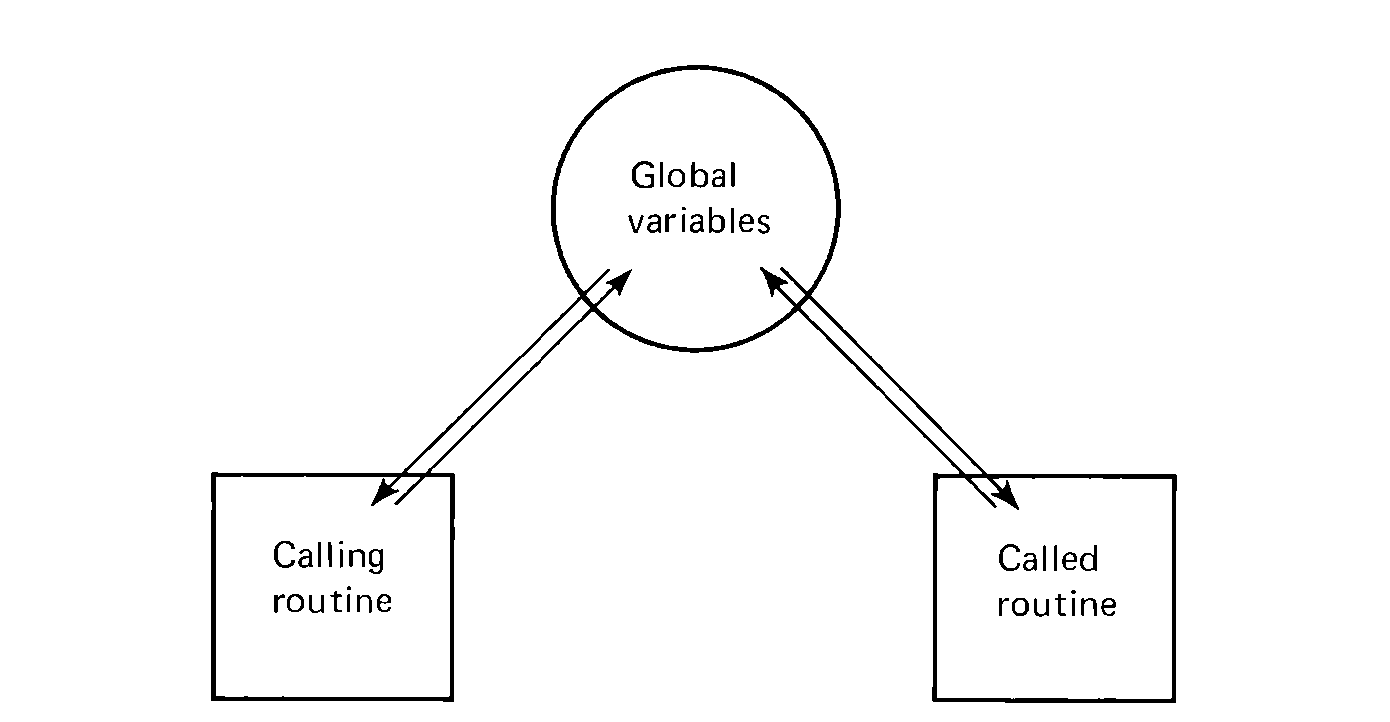 FIGURE 6.3 Global variables (global variables are shared
by several routines in a program; many routines may load and
store from these global locations).
FIGURE 6.3 Global variables (global variables are shared
by several routines in a program; many routines may load and
store from these global locations).
In the writing of a program of many subroutines, global variables are often declared first. Then the code for subroutines is included, followed by the main program. The code for each subroutine would consist of first the declarations of its local variables, and then its prologue, code, and epilogue. Variations from this basic scheme are not uncommon. Each subroutine should be written as a separate package and should be well commented. A short paragraph at the beginning of the subroutine should explain what the subroutine does, what it assumes, what registers it affects, and what other subroutines are called.
Following this format, would require rewriting subroutine SUMMER.
The subroutine SUMMER used as an example in the last section is indeed a bona fide subroutine, but it is a very special purpose one. It always sums exactly 10 elements of the array INCOME. If we wanted to sum only the first five elements of INCOME, we would have to write another subroutine. If we wanted to sum the first 10 elements of some other array, we would again have to write another subroutine.
Rather than write separate subroutines for all of these basically similar functions, we write one general purpose subroutine. Parameters are used to specify those parts of the subroutine which may vary. For the SUMMER function, it is reasonable to assume that the array being summed and the length of the array may differ from one call of the subroutine to another. Thus, we define a function, called SUM, with two parameters. Parameters are also called arguments.
To refer to the parameters, we give them names. There are two types of parameter names. When we discuss the general subroutine, we use formal parameters, which are simply the names of the parameters. For any particular call of the subroutine, it is necessary to specify the specific variables to be used with the subroutine for this call. These specific variables are the actual parameters.
One of the major problems with subroutines is how to pass parameters. The calling routine knows, for each call, what the actual parameters are. It is necessary to transmit this information from the calling routine to the called routine somehow. The problem is, how? As with many problems in programming, many different solutions to the problem have been proposed. Each method may require a small amount of code in the calling routine to set up the parameters. This is called the calling sequence of the subroutine.
One of the most common solutions for assembly language programs is to pass parameters in the programmable registers of the central processor. In MIX, the A and X registers can be used to pass two five-byte-plus-sign numbers, or up to 10 characters. The index registers can pass small numbers or addresses. The return address can be considered as just another parameter which, for the MIX computer, is always passed in the J register. A function value is a parameter which is passed back from the function to the calling routine through the registers.
If values are passed into or out of a subroutine in the A and X registers, they can be accessed directly and used in the subroutine immediately. Often, however, a parameter may not fit into the A or X register. For example, for a subroutine which adds the elements of an array, we need the length of the array (a number easily passed in a register) and the array elements. However, the array cannot be put in the registers (unless it was a very small array), so a pointer to the array, its address in memory, is passed instead. This requires the elements of the array to be accessed indirectly, generally by using indexed or indirect addressing.
If registers are used to pass the address and length of the array to be summed, we can write a SUM subroutine which will add the elements of the array and return the value in the A register as follows.
An alternative subroutine which does not use double indexing is
The calling sequence for passing parameters in registers requires that the registers be properly loaded before the JMP to the subroutine is executed. For the SUM function above, we could sum the two arrays P and Q, whose lengths are equal and equal to the contents of location N, by
Another way to pass parameters is to use global variables. In this method, special global variables are declared which serve as the parameters for the subroutine. When a routine wishes to call the subroutine, it copies the actual parameters into the special global variables and then simply jumps to the subroutine. The subroutine accesses the parameters through the global variables.
For our array summing subroutine, we could declare two global variables, ARRAYADD and LENGTH.
This version requires indirect addressing, and specifically post-indexed indirection. This could be eliminated, as the double indexing was above, by loading from ARRAYADD into I1 and then incrementing register I1 in the loop. Or the program can modify itself by substituting the actual parameter into the code before executing it. In this case, SUM would be written as
Substituting the parameter directly into the code may be acceptable if the parameter is used in only a few instructions in the subroutine, but generally indexing or indirection is a better method of accessing a parameter.
The use of global variables to pass parameters is similar to the use of registers to pass parameters, since registers are essentially just global variables with certain special properties and faster access times. However, use of global variables means that the number and size of parameters are not limited by the number and size of the registers. If a subroutine in MIX had 10 parameters, we could not pass the parameters in the registers, since there are only 8 registers. We would not be able to pass even three parameters if these parameters were each a full five bytes plus sign, since index registers are too small for such parameters. Only the A and X registers can be used to pass full-size parameters. Thus the use of global variables has certain advantages over the use of registers.
There are some problems with the use of global variables, however. Sometimes it is difficult, or inconvenient, to have to allocate global variables. Both the calling and called routines (which may be written by different programmers) must agree upon the location and names of these global parameters. Thus it is not possible to simply pick up a subroutine and use it; it is necessary to also allocate the appropriate global variables.
An alternative method of passing the parameters is to have the space for them be allocated in the subroutine to be called. This means that the subroutine is self-contained and need not reference, nor have allocated, global variables. Notice that the same amount of space is needed, and the parameters would still be accessed in the same manner; the question is simply where to put the parameters. One possibility is in global memory space, another is local to the called routine.
But if the parameters are to be put in the called routine, how is the calling routine to refer to the memory locations where the parameters are to be put? A subroutine should be treated as a black box. No other routine should make any assumptions about how it is internally structured. To do so invites possible errors in the program if the subroutine must be rewritten. The only information about a subroutine which should be necessary outside that subroutine is the location of the entry point, the parameters needed, and the function of the subroutine. It would be possible to require the definition of two entry points for each subroutine: one as the address of the code to which control should be passed to start execution of the subroutine, and the other the beginning address of a block of memory where the parameters should be put.
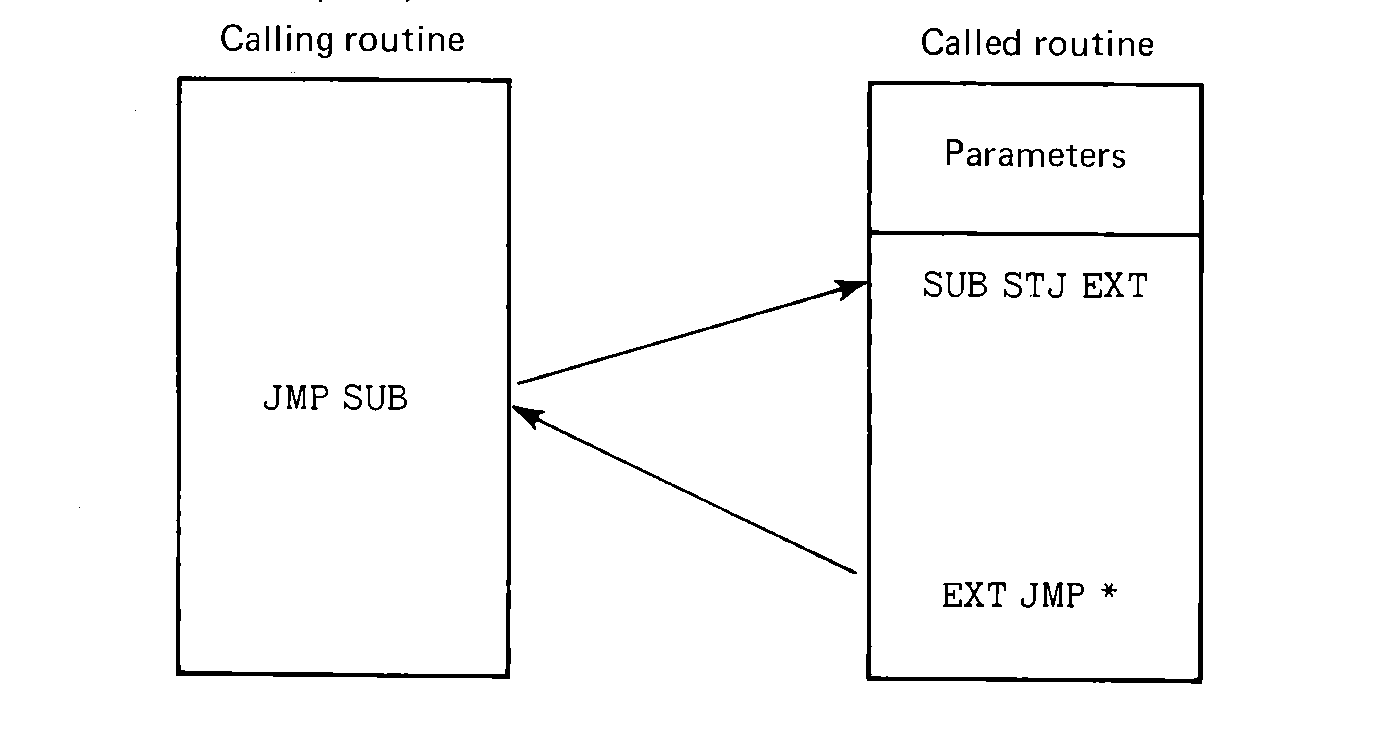 FIGURE 6.4 Parameters passed before
the entry point (parameters are
passed by placing them in the memory location before the entry
point).
FIGURE 6.4 Parameters passed before
the entry point (parameters are
passed by placing them in the memory location before the entry
point).
More often, however, these two addresses are combined, so that only one address need be defined to use a subroutine. To execute the subroutine, control is transferred to the entry point. This same address is also the address of the first location after the locations where the parameters are to be put. Thus the block of memory locations for passing parameters is just before the entry point to the subroutine. For a subroutine with an entry point SUB, for example, control is transferred to the subroutine by a JMP SUB. The first parameter is passed in SUB-1, the second parameter in SUB-2, the third in SUB-3, and so forth.
For our array summing routine, SUM, the code would look like
For a system like the MIX computer, however, passing the parameters just before the entry point can cause definite problems. Specifically, if the subroutine is a forward reference then we cannot use expressions like SUB-1, SUB-2 in our program. Also (as we will see later in Chapter 7), some loaders do not allow expressions which involve entry points. Thus there may be problems with passing parameters in the calling routine.
Still the parameters must be passed from calling routine to called routine in some locations which are mutually accessible by both routines. If the parameters are not passed globally, or in the called routine, the natural place is the calling routine.
If the parameters are passed in the calling routine, the calling routine will have no difficulty accessing them. How does the called routine find them, however? What information does the called routine typically have about the calling routine? Only one thing: the return address. How can the return address be used to locate the parameters? The parameters cannot be put before the return address (as they were put before the entry point when passed in the called routine), since this will be the code which is executed just before the subroutine is called. Thus they must be placed after the call to the subroutine.
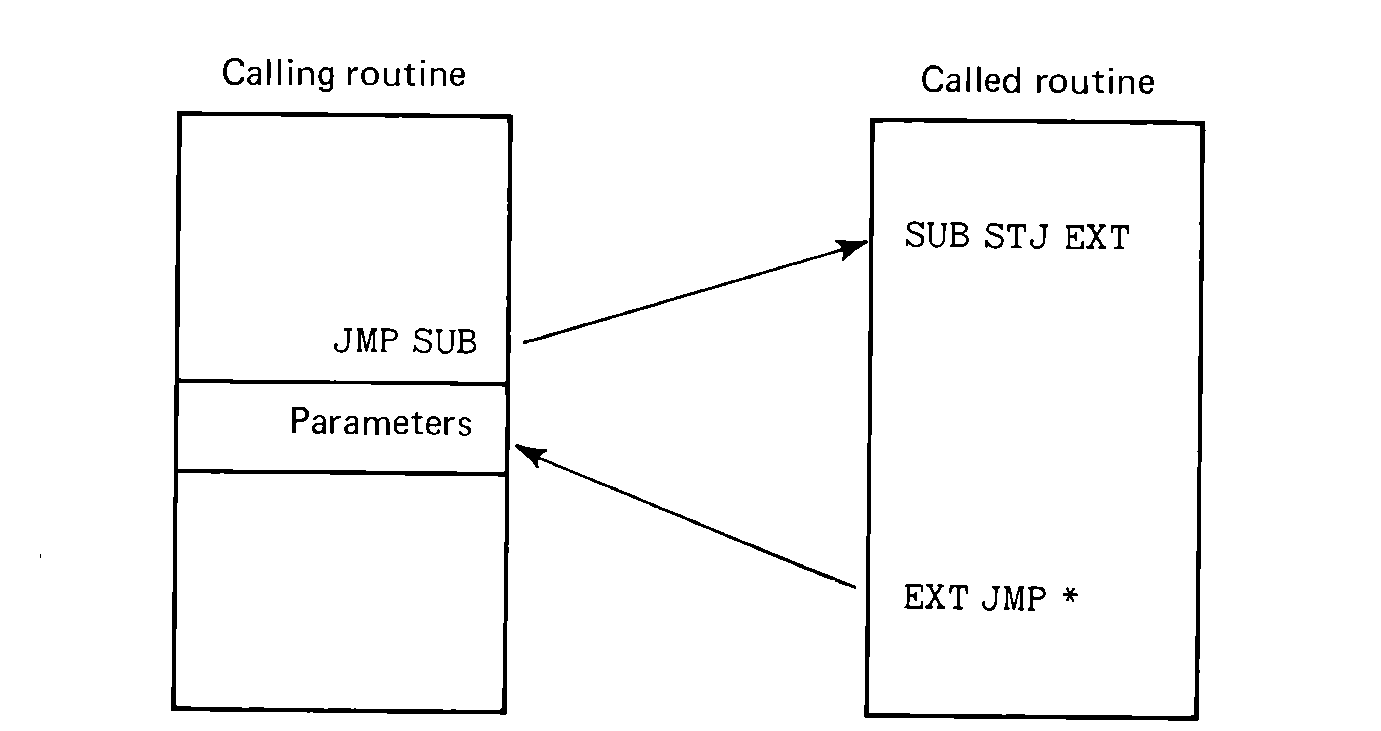 FIGURE 6.5 Parameters passed after
the subroutine call (either the main program or the subroutine must
remember to jump around the parameters).
FIGURE 6.5 Parameters passed after
the subroutine call (either the main program or the subroutine must
remember to jump around the parameters).
This causes one minor problem: how does the subroutine return control to the calling routine without executing its parameters as instructions, by mistake? There are two standard solutions. One is to place a jump around the parameters immediately after the call to the subroutine. In this case, our calling sequence is
To access parameters, we must fetch them indirectly through the return address. Often the return address is loaded into a register to facilitate this. For example, our SUM subroutine (for the calling sequence above) might be
The other standard solution to the problem of keeping the parameters from being executed is to require a subroutine with n parameters to return, not to the address R which is passed as the return address (in the J register) but to return to the address R + n. In this way, the parameters are skipped over by the subroutine. This allows a calling sequence like
The technique of passing parameters in the calling routine, as described in the last section, is widely used. In addition to a number of other advantages, the calling sequence is shorter than many of the other techniques. Since the parameter list is known at the time that the subroutine call is written, and is constant for that call, it can often be written directly after the call, eliminating the need to move the parameters into registers, global variables, or the called routine.
For many programs, an examination of the subroutine calls shows that the same parameter list is being used over and over again for different calls, sometimes even to different subroutines. Consider a program which manipulates vectors. We may have the following subroutines (among others),
| ADD(p,q,n) | Add the vector p to the vector q. | |
| SUB(p,q,n) | Subtract the vector p from the vector q. | |
| COMP(p,q,n) | Compare the vector p to the vector q. Set the condition indicator. |
 FIGURE 6.6 Parameters passed in a table (the address of the table is placed
in a register -- typically, an index register).
FIGURE 6.6 Parameters passed in a table (the address of the table is placed
in a register -- typically, an index register).
To prevent this waste of memory, another parameter passing technique is to pass the parameters in a table. One table is allocated for every different set of actual parameters, thus there are never more tables than subroutine calls. The table is simply a list of the actual parameters of the subroutine call. The address of this table is put in one of the index registers before control is transferred to the subroutine. Thus, the calling sequence is
For the example above, the calling sequence would be
The subroutine accesses the parameters by indexing, through the register pointing at the table, to get the specific parameter desired. Notice that passing parameters immediately after the call in the calling routine is basically the same idea, except that the two addresses passed in the table method, the address of the table and the return address, are combined into simply the return address, which is passed in the J register.
On machines or systems which facilitate the use of stacks, parameters are generally passed on a stack. A little thought shows that the last-in-first-out (LIFO) nature of the stack structure matches the last-called-first-returned nature of subroutine calls.
A stack calling sequence consists of the calling routine pushing onto the stack all parameters. The called routine pops these parameters off the stack and uses them. The return address can also be passed on the stack.
The real advantage with using stacks for passing parameters is when subroutines are nested. Since parameters are always added to the top of the stack, a subroutine need not consider which subroutines call it, nor what subroutines it calls, as long as each subroutine removes from the stack everything that it puts on the stack.
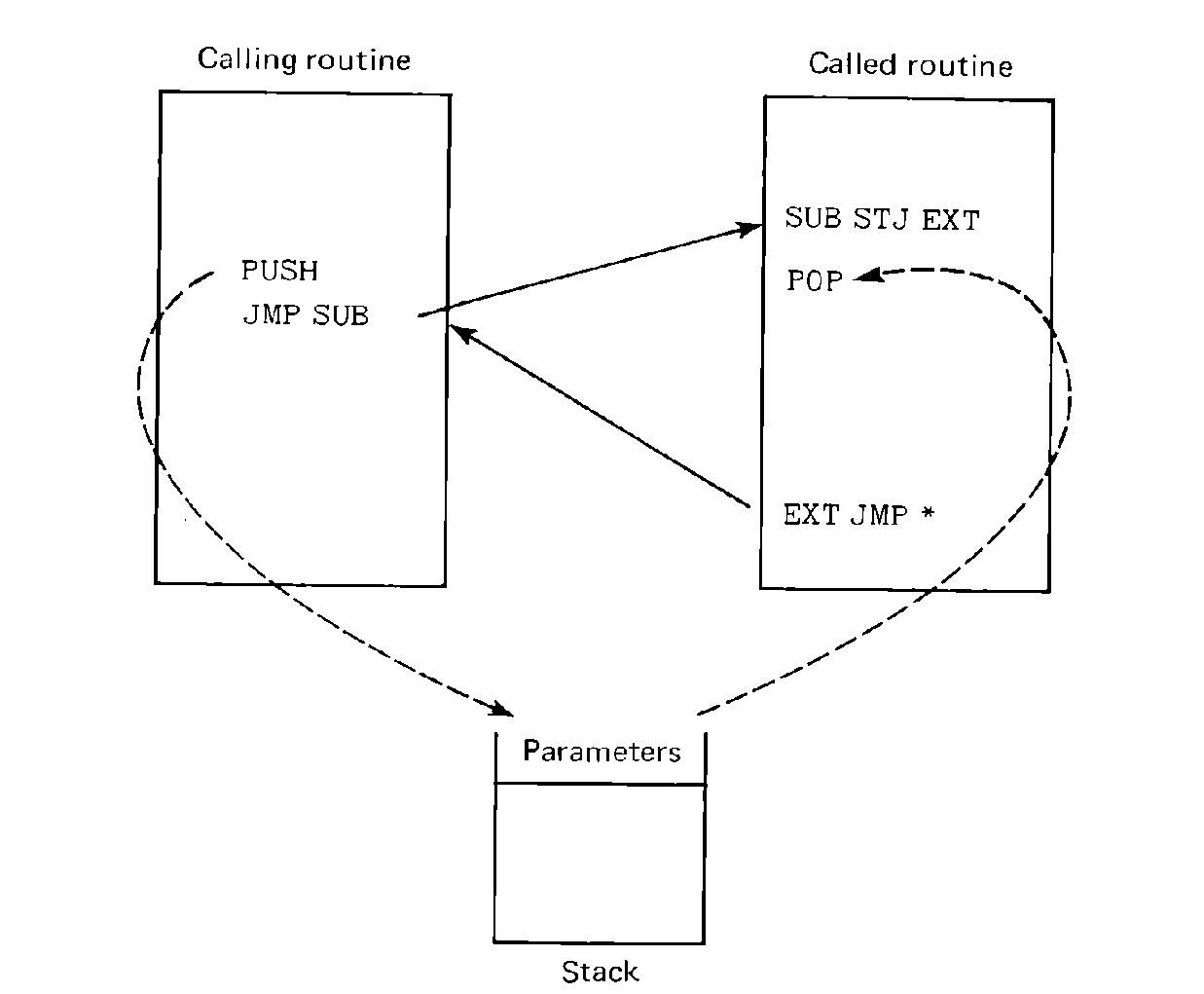 FIGURE 6.7 Parameters passed on a stack (parameters are
passed to the called routine by pushing them onto a stack; the
called routine accesses them by popping the stack).
FIGURE 6.7 Parameters passed on a stack (parameters are
passed to the called routine by pushing them onto a stack; the
called routine accesses them by popping the stack).
Each of the methods of passing parameters which we have explained has been used by assembly language programmers, and each one has its advantages and disadvantages. But assembly language programmers are not restricted to only these techniques; they have the freedom to use any logically consistent method of passing parameters. Often programmers use a mixture of these techniques, passing several parameters through the registers while passing others as global variables or in the calling or called routine. The only important thing is that both the calling and called routine agree on how the parameters are to be passed. An assembly language programmer has the freedom to choose an appropriate method for each different subroutine.
This also calls for the responsibility to check that parameters are passed correctly in all cases. If each different subroutine has a different method of passing parameters, then this can become a major source of errors. To avoid this, programmers often adopt one standard calling sequence for the entire program. This eliminates a number of potential problems for the programmer, and hence means the program is more likely to be finished sooner.
Another source of standard calling sequences are subroutine libraries and compilers for higher-level languages. In the first case, a standard calling sequence increases the usability of the set of subroutines in the library. If you wish to use one of the subroutines in the library, you need only use the standard calling sequence to access it.
For compilers, when a higher-level language instruction calls a subroutine, the correct calling sequence must be generated, and when a subroutine accesses a parameter, the code which is generated must be consistent with the calling sequence. Thus, for most compilers, one standard calling sequence is used for all subroutines and functions. Often these calling sequences are published and available to any programmer who is interested. This allows the assembly language programmer to combine routines written in the higher-level language and assembly language.
A typical situation in which this is done is when a central computation is crucial to the speed of a program and must be carefully programmed to take an absolute minimal amount of time. In these cases, the central computation may be written as an assembly language subroutine which is called by a higher-level language main program. This allows the most important code to be written in assembly language without making it necessary to code the entire program (which might be quite large) in assembly language.
Another situation may involve I/O. I/O is often difficult in assembly language, since it requires considerable code to properly format, block, and buffer data for input or output. In this case it is often convenient to have an assembly language main program call subroutines written in a higher-level language to perform the I/O.
Notice that when combining routines in different languages, the higher-level language compiler normally has a fixed method of passing parameters, which-ever method seemed best at the time that the compiler was written. Thus, such routines can be combined with assembly language routines only because the assembly language routine can be written to match the higher-level language calling sequence. This means that it is generally not possible to combine routines written in different higher-level languages or even compiled by different compilers for the same language. For example, the RUN Fortran compiler for the CDC 6600 computer passes parameters in its registers, unless there are more than six, when the extra parameters are passed before the entry point in the called routine. The FTN Fortran compiler for the same computer, on the other hand, uses a table. Thus routines compiled by these two compilers cannot be combined, because they use different standard calling sequences.
In the previous section, we considered how information could be passed to a subroutine. In this section, we consider what information should be passed. The decision as to what information should be passed to a subroutine about a parameter often helps to determine how that parameter is passed. For example, the two most common kinds of information about a parameter are its address and its value. If its value is passed, then it may be necessary to utilize the A and X registers to pass the parameters. If more than two parameters are passed, this may mean that the parameters cannot be passed in the registers. On the other hand, if addresses are passed, then they can easily be passed in the index registers, allowing six or eight (if the A and X registers are used also) parameters to be passed in the registers.
Notice that although we are discussing what information should be passed to a subroutine, we do not address here the problem of what the parameters of a subroutine should be. That is a creative decision which is part of the programming problem. Here we are concerned only with how to code a problem once the program has been defined.
Parameters can be defined to have one of three kinds of effects on a subroutine. They can be input parameters, output parameters, or both input and output parameters. An input parameter is a parameter whose initial value (the value of the parameter at the time of the subroutine call) is used in the program. Both the array parameters and the length of the array parameter in the SUM subroutine used as an example in Section 6.2 were input parameters. An output parameter is a parameter whose value is defined by the called routine and returned to the calling routine. The sum of the elements of the array was an output parameter of the SUM subroutine. Some parameters may be both input and output parameters. Notice that if a parameter is neither an input parameter nor an output parameter, it need not be a parameter.
These different types of parameters result in different types of information being passed between routines:
One type of information about a parameter which can be passed is its value. If the parameter is a simple variable or an element of an array, its value is loaded from memory and passed to the subroutine. Often the value is passed in a register.
Notice that this type of subroutine call, a call by value, is most suitable for input parameters. If a value of a parameter is passed into a subroutine for an output parameter, we have wasted our efforts to pass it in, since it will not be used. Furthermore, the subroutine lacks the ability to change the value of the parameter. At best, it can change the copy of the value of the variable which is passed in, but it cannot change the value of the actual parameter, which is in memory. The subroutine does not know where in memory the parameter is; it knows only the value that the parameter had when the subroutine was called.
To allow for output parameters, a variation on call by value is used. In this variation, call by value/result, the values of input parameters are passed into the subroutine, and the subroutine passes out the values of the output parameters which may then be used or stored by the calling routine. This allows both input, output, and input/output parameters. It is typically used by assembly language programmers.
Still there are some problems with call by value. Specifically, it is difficult to use call by value, or call by value/result when the parameter is an array or table. To pass an array by value would require copying the entire array and passing each element into the subroutine. This would be prohibitively expensive, in both time and space, for most situations.
A second type of information about a parameter which can be passed is its address. This form of passing parameters is call by reference, or call by address. The address of the parameter is passed to the subroutine. If this parameter is an input parameter, its value can be determined by loading indirectly through this address; if it is an output parameter, its new value can be stored indirectly through the passed address.
Call by reference is typically used whenever arrays or tables are passed as parameters. In this case, the base address of the array is passed into the subroutine. The subroutine can then index into the array and reference individual elements of the array without the entire array needing to be copied.
Call by reference can be easily used with any of the parameter passing mechanisms considered in Section 6.2, and so is often used as a standard calling technique. It is particularly common for compilers, like Fortran and PL/I compilers, to use call by reference. For a Fortran compiler, the code for a subroutine call such as CALL SUB(A,B,C,D,5), which uses call by reference and a calling sequence which lists the parameters in the calling routine, becomes simply
Some problems with this approach do occur however. Since parameters in Fortran are allowed to be array elements, the call might be CALL SUB2(A,B(J)) where B is an array, and J an integer index. For call by reference, the address of B(J) is computed at the time of the call, and stored in the parameter list. Thus the code for this, using a parameter list in the calling routine as above, is
A similar problem is caused by expressions. If the call is CALL POLY(P+Q*2, RESULT), the value of the expression P+Q*2 is quite easily calculated, so a call by value approach is straightforward. For call by reference, we must pass an address, and an expression has no obvious address associated with it. This problem is resolved by computing the value of the expression and storing that value in a temporary variable. Then the address of the temporary variable is passed to the subroutine. Thus, for the above call to POLY, a calling sequence is
In some subtle cases, call by reference and the lack of concern in the subroutine for what kind of parameter is being passed in can cause rather obscure bugs in a program. One of the problems with call by value is that it has no provision for output parameters, parameters whose value should be set by the subroutine. Call by value/result has provision for output parameters, but may result in a lot of unnecessary copying. By passing an address to the subroutine, as in call by reference, the subroutine can easily load and store in any parameter. And that is the problem. The subroutine can load and store in any parameter, including those in which it is not intended that it should store by the calling routine.
The classic example of this is as follows. Consider the subroutine,
Now consider the same subroutine for a CALL ZERO(5). The calling sequence is
The simple variable and constant clobbering problem can be solved by treating these values as expressions, and copying them to temporary variables whose addresses are passed to the subroutine. If these are clobbered, there is no problem, as these values are never used by the calling routine. This is similar to call by value/result, only with addresses instead of values.
The problems of call by reference bring up a larger problem relating to subroutines in higher-level languages and how they are implemented. Given a definition of a subroutine, what does a call on that subroutine mean? This is a subtle question and not an easy one to understand or answer. But consider the subroutine ZERO defined above. The meaning of CALL ZERO(J) is obvious: set the variable J to zero. But what is the meaning of CALL ZERO(5) or CALL ZERO(P+Q)? Some programming languages never really worry about the problem, assuming that "strange" subroutine calls are errors, and hence, let the programmer beware! Others have carefully defined what a subroutine call should mean. Algol has one of the most commonly referred to definitions.
The rules of the Algol programming language state that when a subroutine is executed, the results of that execution should be identical to the execution of the body of the subroutine with all occurrences of the formal parameters replaced by the names of the actual parameters. This means that the effect of a subroutine call should be the same as if the subroutine call were removed and the text of the subroutine body were copied into the calling routine where the call was, substituting the strings of characters which define the actual parameters everywhere that the corresponding formal parameter occurs. This is called the copy rule or the replacement rule.
As an example, consider
This is a simple and seemingly reasonable definition of what a subroutine call should mean. It corresponds to what most people think subroutines should mean. However, there are some subtle complexities which are often overlooked.
Consider the subroutine SWAP(A,B) defined by
This simple example should illustrate not only that the copy rule may result in unexpected results, but also that it cannot be implemented by call by value or call by reference. For either call by value or call by reference, the values or addresses of the parameters are calculated and fixed at the time of call. To properly implement the copy rule, a new parameter passing technique, call by name, is used. For call by name the values or addresses of parameters may change during the execution of the subroutine. This means that it is necessary to recalculate the value or address of each parameter each time it is used in the subroutine. This is done by creating a small subroutine with no parameters for each parameter. This subroutine is called a thunk. The thunk for a parameter is called by the subroutine whenever the parameter is about to be used. The thunk calculates the current address of the parameter and returns it to the subroutine. The subroutine then uses this address to access the parameter.
As an example, consider the above SWAP routine. Assume that each thunk for a parameter will leave the current address of that parameter in index register 6, and that the calling sequence is to put the addresses of the thunks of the parameters immediately after the call in the calling routine. Then the calling sequence for CALL SWAP(J,G(J)) is
Some improvements can be made. Indirect addressing (with preindexing) can eliminate the need for index register 2. But the overhead of the code and calls for the thunks is fundamental to call by name, so minor improvements cannot really help much. Also, some systems require two subroutines per parameter, one to return the value of the parameter and the other to store a new value into the parameter. This seeks to prevent undesired storing into parameters in the way that call by value prevents illegal stores which are possible in call by reference.
Given the desire to implement the copy rule, the use of thunks is necessary. However, thunks are a very expensive way to access parameters. Thus call by name is seldom used. Call by reference is the most common technique with call by value or call by value/result also enjoying reasonable popularity. As always, an assembly language programmer has the freedom to pick and choose as appropriate. The techniques can even be mixed in assembly language so that of three parameters, one may be call by name, another call by reference, and the third call by value/result. Typically, expressions and simple variables are passed by value, where possible, while arrays and tables are passed by reference.
The cost of a particular programming technique is generally measured in two ways: space and time. We have said that call by name is a very expensive method of passing parameters. Can we formalize that statement to some degree by showing just how expensive the use of call by name is, relative to call by reference or some other scheme? Yes, we can, but let us first consider the cost of using subroutines at all, versus not using them.
Consider a program which uses a subroutine to perform some task. Looking first at space, suppose that the subroutine is called from m different places in the text of the program, and that the body of the subroutine is k words long. The body of the subroutine does not include the prologue or epilogue of the subroutine. Now, if the subroutine were to be bodily written out in each of the m different places where it is called, then m × k words would be needed for the subroutine part of the program. By using a subroutine, however, we reduce the code for each of the m calls to 1 word each, plus the body of the subroutine (k words) plus the prologue and epilogue. The prologue saves the return address (STJ) and the epilogue returns to the calling program (JMP). So with the subroutine, the number of words needed is m + k + 2. For the cases where m + k + 2 is less than m × k, using a subroutine takes less space. Obviously, for m = 1 (subroutine only called from one place) or k = 1 (subroutine only one word long), we should not use a subroutine, if we are worried about space.
These equations are, in fact, too simple. The subroutine probably has parameters (p of them) and needs to save and restore registers (r of them). The prologue is at least 1 + r words, the epilogue is 1 + r words, and the calling sequence is p + 1. In addition, if call by name is used we must consider the space needed for the thunks (at least three words per parameter) and the additional code that is needed to access the parameters (if any). Thus the actual space used by a subroutine is relatively complex. In general, however, as long as your subroutine is longer than your calling sequence (k > p + 1) and your subroutine is called in more places than the number of words in the prologue and epilogue (m > 2 × r + 2), then using a subroutine probably saves space.
Another major consideration is time, and it may be more important than space. More computer systems charge for time than space, so as long as your program can fit in core, time is often of crucial importance. To calculate the amount of time needed for a subroutine, we need to know the number of times it is called, n. Notice that the number of times it is called is different from the number of places where it is called. Given that there are m different calls to the subroutine, some of these may be skipped due to conditional branching, and others may be in loops so that the subroutine is called over and over again although it is called from only one place. Thus we may have m > n, m = n, or m < n.
Now for each call of the subroutine, the subroutine will take some average execution time, f, to execute the body of the subroutine. Thus if no subroutine is used, the program will take n × t time units to execute the function of the subroutine. If a subroutine is used, each call now takes 1 time unit for the JMP to the subroutine, 2 time units for the STJ, t time units for the subroutine body, and 1 time unit for the return jump. Thus, if a subroutine is used, our time is n × (t + 4), and in all cases, the use of a subroutine takes more execution time. The times become even worse when you add the additional time to set up the calling sequence, save and restore the registers, and fetch parameters.
If using subroutines always takes longer, why are they used? First, consider that if f is on the order of 1000 or 1000000 time units, the extra 4 or so time units per call are of minimal importance. Second, we have considered only execution time in this analysis. For a complete view of the cost of not using subroutines, the extra cost of programming time, keypunching time, assembly time, load time, and debug time, all of which tend to be larger for larger programs, must be considered. Except for trivial subroutines, the relative cost of using subroutines is generally far outweighed by the convenience of using subroutines. Subroutines make programs easier to read, to write, and to understand (hence debug) when used properly. Although one must be careful as to how to write subroutines and how to pass parameters, subroutines are considered good programming practice.
There are several other aspects of subroutines which a good programmer should be aware of, although the use of these techniques is relatively rare. We discuss them briefly here simply to acquaint you with the ideas.
It is sometimes convenient to write the body of one subroutine which is used by several entry points. This saves unnecessary duplication of code. For example, consider a pair of subroutines to calculate the sine and cosine of an angle in radians. These routines could be written as two separate subroutines. However, it is well known that sine(x) = cosine(x + pi/2). This can be exploited by writing one subroutine with two entry points. The cosine entry point adds pi/2 to its parameter and then jumps directly to the code for the sine calculation. The basic structure for this in MIX might be, assuming that the parameter is passed by value in the A register.
Some subroutines function as decision makers, testing some condition. The result of the test requires the execution of different code in the calling routine for each outcome. On the MIX machine, it is possible to effect this by having the subroutine set the condition indicator before it exits. The condition indicator can then be tested in the calling routine after the call. For example, to compare two vectors, P and Q, of length N, we could use a calling sequence
An alternative to this approach is to pass the addresses of the branches to the subroutine as parameters, and allow it to transfer control directly to the appropriate code. In this case the subroutine does not always transfer to the location following the call, but has multiple exits.
A combination of multiple entry points and multiple exit points can also be used. Suppose we wish to write a generalized search subroutine. The subroutine will search a table for a particular value (passed in the A register) and, if found, return its index in index register 1. An error condition exists if the value is not found. We construct a subroutine with two entry points. One entry point is used for performing a search. The other entry point is used to define where control should transfer to if the value is not found. It requires one parameter, the error address. This entry point sets internal variables so that if the other entry point is called later and the value is not found, the search subroutine will not return to the location after the entry point, but rather return to the error address defined by the call to the other entry point. This routine would have multiple entry points and multiple exits.
Another variation on subroutine calling sequences is to allow a variable number of parameters. For some subroutines this may be very useful, as in a subroutine to calculate the maximum value of its parameters. It would be ridiculous to have to write separate subroutines for finding the maximum of 2, 3, 4, 5, 6, or more parameters. What is needed is one subroutine which allows a variable number of parameters.
Another use for this feature is with subroutines which have a long parameter list, most of which will not change from call to call. In these cases, the parameters are ordered so that the least frequently changing (or those assumed to be the least frequently changing) occur last in the list. Then if the last k parameters are the same as the previous call, they are simply not listed.
To properly effect this, two things are needed. First, the subroutine must keep copies of the previous parameters for possible use in subsequent calls. Second, there must be some way of determining the number of parameters. The first problem is simply a problem for the programmer of the subroutine to look after by storing copies of all parameters in local variables. The second may require the changing of the calling sequence.
Basically, what is done is to add another parameter which indicates the number of parameters in the parameter list. One technique places a special value after the last parameter in the parameter list. For example, in call by reference, all parameters are addresses. On the MIX machine, all addresses must be in the range 0 to 3999. Thus, we can use either a negative number, or a number larger than 3999 to indicate the end of the parameter list. For this approach, a call to a MAX function with parameters 0, X, and Z might be
Another approach is to make the first parameter the number of parameters in the list. This has the advantage of being usable for either call by name, call by reference or call by value and careful coding can mean that no extra space is needed for a flag at the end of the list. In the simple case, the calling sequence is simply
In some situations, the variable part of a subroutine is not a variable or constant that is used, but a subroutine or function which is called. This would seem to rule out the use of a subroutine, but in fact a subroutine or function can be passed as a parameter to a subroutine quite easily. Call by reference or call by name are almost always used since what is needed is the address of the function parameter so that it may be called. (Thunks are simply special functions which are passed, by reference, to another subroutine.)
The major problem which arises is in the calling sequence of a function which is passed as a parameter. Since the function is not known by name when it is called, the calling sequences for all functions which may be the actual parameter for the formal parameter must be the same. Often a thunk is created for each function, so that the calling sequence for the function in the subroutine is the simplest possible, with at most one parameter, or more commonly with none. Passing a function as a parameter is a technique sometimes used in programs for numerical analysis.
In addition to the different types of parameters (call by value, call by reference, call by name) and different ways of passing them (in registers, globally, in called routine, in calling routine, in a table), there are different types of subroutines. These classifications are made on the basis of the programming techniques which are used, rather than on the subject matter of the subroutine.
One of the easiest to define but sometimes most difficult to implement is the reentrant subroutine. A subroutine is reentrant if it is non-self-modifying. Non-self-modifying means that the subroutine never changes. This is also called pure code, and requires quite simply that there be no store instructions whose operand is an instruction of the subroutine.
On the MIX computer, reentrant programs are quite difficult to write, since the standard subroutine call mechanism generally involves a STJ instruction to save the return address. Also, the saving and restoring of registers often involves storing index register values directly into the instructions which restore them. Both of these coding practices are invalid for reentrant programming.
How can subroutines be written which never store? They probably cannot be written, but luckily this is not quite the restriction. The restriction is that a subroutine cannot store in the subroutine, but it can store outside the subroutine. Typically, what is done is that the calling routine is required to pass, as a parameter, by reference, in one of the index registers, a large array which can be used by the reentrant subroutine for the temporary storage of data, return addresses and old register values. This allows the storage of variables outside the subroutine itself, meaning that the subroutine itself can be pure code.
Reentrant routines are useful in relatively rare circumstances. One situation where they are useful is in a computer system with multiple CPUs. Each CPU would have its own ALU, control unit, and registers, but they may share memory. To avoid having two copies of the same program, that program can be written as a reentrant program. Each CPU can execute the same code, at the same time, but with different work areas pointed at by their different register sets.
By analogy, consider a program to be like a cookbook. When a cook uses a recipe, he may need to take notes about what is done and at what time (local variables). If he writes these in the margins of the book, then his notes may confuse another cook trying to use the same recipe at the same time, especially if that cook is taking her own notes by erasing the first cook's notes and writing her own in the same place. For the cooks to be able to share the cookbook, the cookbook must be reentrant, with all notes being kept on a separate piece of paper for each cook.
Similarly, each CPU can execute the same subroutine or program only if all variables are kept in separate work areas and the code is pure and reentrant.
A less stringent requirement for a subroutine is serial reentrancy. A subroutine is serially reentrant if it works correctly whenever it is executed, perhaps by multiple processors, so that each processor executes the subroutine completely before the next processor starts executing it. That is, as long as only one processor at a time is executing the code, it works correctly. In terms of our cook/cookbook analogy, this means that several cooks can use the same cookbook but only one can use it at a time. Obviously, a cook can make notes in the cookbook, as long as either they are erased before she finishes with the cookbook and gives it to another cook, or the next cook erases them before he starts.
A serially reentrant subroutine can store information in local variables in a subroutine, as long as these local variables are properly initialized before the subroutine is executed again. Thus the STJ method of using the return address is acceptable, since the next time the subroutine is called that location will be reset properly for the call.
A simple example of a non-serially reentrant program is the following routine to return the A register as the sum of the array whose base address is in index register I1 and whose length is in index register I2.
Another type of subroutine is the recursive subroutine. A recursive subroutine is a subroutine which may call itself. Recursive subroutines are almost never written in assembly language and cannot be written even in some higher-level languages, such as Fortran. The problem is of course that the second call on the subroutine may clobber the return address passed to the subroutine by the first call, and hence the subroutine will never know how to return to the first call. Recursive subroutines are often written as reentrant subroutines and use a stack to hold return addresses and local variables.
Coroutines are another special type of subroutine, or rather a subroutine is a special type of coroutine. A called and calling routine exist in a specific relationship. The calling routine calls the called routine and the called routine returns control to the calling routine. The called routine is, in some sense, subservient to the calling routine. Hence the name subroutine.
A coroutine or a set of coroutines do not restrict themselves to a calling-called relationship but rather work more as equals. A coroutine does not simply call another coroutine, but also supplies a return address to which the called coroutine should return. When the called coroutine returns, it also passes an address which is where it should be resumed next. Thus each coroutine is equal, calling the other where it left off and specifying the address where it should be resumed.
For MIX, coroutines are quite easy to implement. A restart address is associated with each coroutine. A coroutine call involves resetting the coroutine restart address for the current coroutine and then jumping, indirectly through the restart address, to the next coroutine.
Although coroutines have their advantages, they seem not to have been adopted by assembly language programmers.
Subroutines are a very important programming technique, especially for assembly language programmers. Subroutines allow redundant code to be grouped together and written only once, saving computer memory and programming time. Most subroutines require parameters to be passed to them, and many methods are used to do so. Parameters can be passed in registers, in global variables, in special parameter areas before the entry point or after the call, or in a table. The parameters themselves may be call by value, call by reference, or call by name, requiring that the value of, the address of, or the address of a thunk for, respectively, the parameter be passed.
Subroutines can save space but always require more time to execute than simply writing out the code repetitively. Subroutines may have multiple entry points or multiple exit points or both. The address of a subroutine or function can even be passed as a parameter to another subroutine.
Subroutines can be reentrant, serially reentrant, recursive, or none of these. Coroutines are programming structures related to subroutines.
Subroutine programming techniques have developed over the years and are part of the common knowledge of programmers. Knuth (1968) has a treatment of subroutines and coroutines, as do the books by Gear (1974) and Stone and Siewiorek (1975). The definition of thunks is due to Ingermann (1961), while coroutines are generally credited to Conway (1963).